Elasticsearch学习
Elasticsearch
暂时只学习个大概的语法,和了解 Elasticsearch
本篇基于 Elasticsearch 8.5.3 版本。
1. 概述
1.1 什么是 Elasticsearch
Elasticsearch 是位于 Elastic Stack 中心的分布式搜索和分析引擎。Logstach 和 Beats 促进采集、合计以及充实你的数据并在 Elasticsearch 中存储它们。Kibana 允许你去交互式的探索、可视化和共享对数据的见解,以及监视这个栈(Elastic Stack)。Elasticsearch 是索引、搜索和分析的神奇所在。
Elasticsearch 为各种数据类型提供接近实时的搜索和分析。不论你有结构化或非结构化的文本、数字数据,还是地理空间数据,Elasticsearch 能以支持快速搜索的方式高效地存储和索引它。你可以以远超简单数据检索和聚合信息的方式去发现你数据中的趋势和模式。而且,随着你数据和查询量的增长,Elasticsearch 分布式的特性允许你的部署能随着它无缝地增长匹配。
虽然不是每个问题都是搜索问题,但 Elasticsearch 在大量实例中提供了处理数据的速度和灵活性:
- 为应用或者网站应用添加搜索框(这个属于搜索问题,也是我们最主要关注的地方)
- 存储和分析日志、度量和安全事件数据
- 使用机器学习,实时自动建模你的数据行为
- 使用 Elasticsearch 作为存储引擎来自动化业务工作流
- 使用 Elasticsearch 作为地理信息系统(GIS)管理、集成和分析空间信息,以及使用 Elasticsearch 作为生物学信息研究工具处理基因数据
除了前两个功能我们重点学习以外,后面三点只做了解,因为太过要遥远了还。
1.1.1 数据输入:文档和索引
Elasticsearch 是一种分布式文档存储。它不像传统的关系型数据库那样按列存储信息,而是存储已序列化为 JSON 文档的复杂数据结构。更像是一种非关系型数据库那样。当以集群方式搭建 Elasticsearch 时,存储的文档将分布在集群中,并且可以从任何节点直接访问(许多分布式中间件也是这样)。
对于 Elasticsearch 而言一个文档就相当于一条数据,索引更像是 mysql 中的数据库中的表。
当一个文档被存储时,它会被索引并且在接近实时(大概1秒内)被完全可搜索。Elasticsearch 使用了一种称之为倒排索引的数据结构,支持非常快的全文检索。倒排索引列出任何文档中出现的唯一单词,并标识每个单词出现的所有文档。
索引可被认作一种文档的优化集合,且每个文档都是字段的集合,字段是包含你数据的键值对。默认情况下,Elasticsearch 索引每个字段中的所有数据,且每个被索引的字段有一个专用的优化数据结构。例如,文本字段被存储在倒排索引中,数字和地理字段存储在 BKD 树 中。使用每个字段的数据结构来聚集和返回搜索结果是让 Elasticsearch 如此快的原因。
Elasticsearch还具有无模式的能力,这意味着无需显式指定如何处理文档中可能出现的每个不同字段即可对文档建立索引。启用动态映射后,Elasticsearch自动检测并向索引添加新字段。此默认行为使索引和浏览数据变得容易-只需开始建立索引文档(插入数据),Elasticsearch就会检测布尔值,浮点数和整数值,日期和字符串并将其映射到适当的Elasticsearch数据类型。
当然你也可以自定义映射,这样就可以明确地定义以完全控制字段如何存储和索引,例如:
- 区分全文字符串字段和精确值字符串字段
- 执行特定语言的文本分析
- 为部分匹配优化字段
- 使用自定义的日期格式
- 使用无法自动检测的数据类型,如
geo_point和geo_shape
1.1.2 信息输出:搜索和分析
除了使用 Elasticsearch 存储文档和检测文档及他们的元数据,但 Elasticsearch 是建立在 Apache Lucene 搜索引擎库之上的,而 Elasticsearch 真正强大的地方在于你能够轻松地访问构建在 Apache Lucene 搜索引擎库之上的全套搜索能力。
Elasticsearch 提供了一种简单,一致的 REST API,用于管理你的集群已经索引和搜索数据。这种方式可以很轻松兼容任何语言。除此之外还可以使用 Kibana 开发者平台提交请求。
1.1.2.1搜索你的数据
Elasticsearch REST API 支持结构化查询、全文查询以及结合二者的复杂查询。结构化查询类似于你在 SQL 中构造的查询类型。例如,你可以在职员索引中搜索性别和年龄字段,并按雇佣日期字段对匹配项进行排序。全文查询,查找查询字符串匹配的所有文档,且返回按相关性——他们与搜索词语匹配程度——排序的文档。
除了搜索单个词语,你也可以执行短语搜索、相似性搜索和前缀搜索,并且获得自动完成建议。
你可以访问使用 Elasticsearch 全部 JSON 风格的查询语言(查询 DSL)的所有搜索能力。你也可以构造 SQL 风格的查询搜索和聚合在 Elasticsearch 中的内部数据,JDBC 和 ODBC 驱动使得各种第三方应用能通过 SQL 与 Elasticsearch交互。
1.1.2.2分析你的数据
Elasticsearch 聚合查询能使你对你的数据构建复杂的摘要,并深入了解关键度量、模式和趋势。聚合查询使你能够对你的数据进行分析,而非仅仅搜索你想要的数据。
1.2 可伸缩性和弹性::集群、节点和分片
Elasticsearch 被构建为始终可用,并且能按需扩展。它是通过天然的分布式来实现的。你可以通过向集群添加服务器(节点)来增加容量,Elasticsearch 自动分布你的数据和查询到所有可用节点。无需改造你的应用,Elasticsearch 知道如何平衡多节点集群以提供规模和高可用性。节点越多越好(视系统规模来否则可能会导致浪费资源)。
这是如何工作的?实际来讲,一个 Elasticsearch 索引只是一个或多个物理分片的逻辑组,其中每个分片实际上是一个独立索引。通过将索引中的文档分布在多个分片上,并将这些分片分布在多个节点上,Elasticsearch 能确保冗余(防止数据丢失),这既能防止硬盘损坏也能在节点添加到集群时增加查询容量。随着集群的伸缩,Elasticsearch 自动迁移分片以重新平衡集群。
有两种类型的分片:主分片和副本。索引中的每个文档都属于一个主分片。一个副本分片是一个主分片的复制。副本提供了数据冗余复制,以防止硬件故障,并增加服务读取请求——如搜索或者检索文档——的容量(增加检索性能)。
索引中的主分片的数量是索引创建时固定的,但副本分片数量可以随时更改而不会中断索引或者查询操作。
容灾
在一个位置发生重大停机的情况下,另一个位置的服务器需要能够无缝的接管。答案是什么呢?跨集群复制(CCR)。
CCR 提供了一种方式自动地从主集群同步索引到作为热备的备份远程集群。如果主集群失效了,备份集群就会接管。你也可以使用 CCR 创建备份集群,以便在地理上靠近用户时,为读请求提供服务。
跨集群备份(CCR)是 主动-被动模式(active-passive)。主集群上的索引是活动的领导者索引,且处理所有写请求。复制到备份集群的索引是只读的追随者。
维护保养
可以使用 Kibana 作为管理集群的控制中心,实时监控和管理 Elasticsearch 集群节点。数据汇总和索引生命周期管理等特性可以帮助你随着实践的推移智能地管理数据。
2. 入门
2.1 安装并启动 Elasticsearch
2.1.1 环境设置:设置max_map_count不然es启动报错
# 查看max_map_count的值,应该是65530 |
确保 docker 被分配了至少 4 GiB 的内存
拉取 Elasticsearrch、Kibana Docker 镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.5.3 |
2.1.2 Docker 部署 Elasticsearch 单机
8.5 版本,当你第一次启动 Elasticsearch 时,将自动进行以下安全配置:
- 生成证书和密钥 对于传输层和 HTTP 层。
- 传输层安全性 (TLS) 配置设置将写入
elasticsearch.yml。 - 将为用户
elastic(默认)生成密码。 - 将为 Kibana 生成注册令牌。
为了的上述的关键信息,这里我们先简单启动一个容器。
- 为 Elasticsearch 和 Kibana 创建新的 docker 网络
docker network create elastic |
- 重建 elasticsearch 容器并运行
docker run --name es01 --net elastic -p 9200:9200 -p 9300:9300 \ |
等待启动,启动完毕后我们会看到如下界面
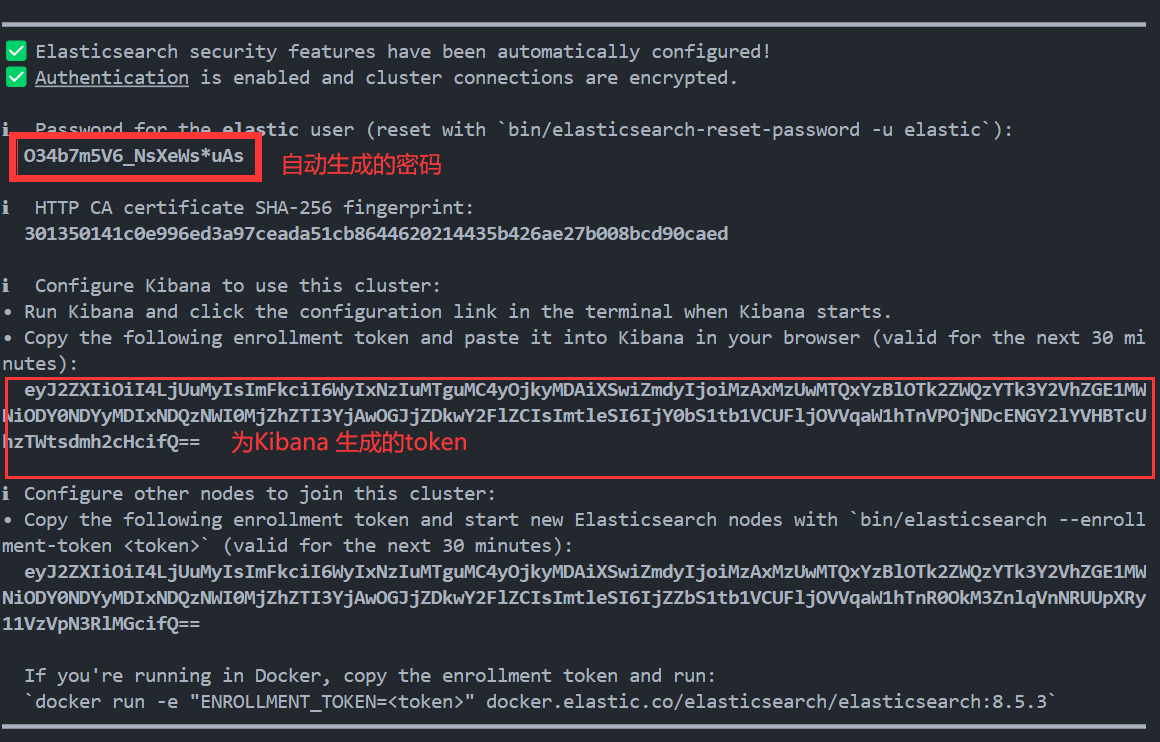
将上述数据保存后进行下一步操作。注意:为 Kibana 生成的 token(半小时有效)
访问页面
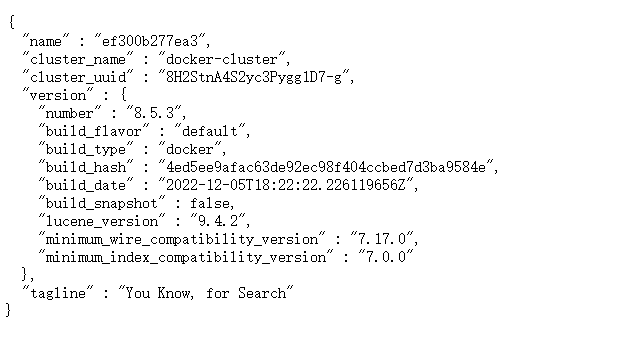
浏览器输入:http://docker主机地址:9200
提示输入账号密码–>输入进入
页面如图,启动成功:
2.1.3 启动 Kibana
另外开辟一个连接,注意elasticsearch实在前台运行,千万别停止!!!
运行 Kibana 容器
docker run --name kib-01 --net elastic -p 5601:5601 -v kb_config:/usr/share/kibana/config -itd docker.elastic.co/kibana/kibana:8.5.3 |
1、等待启动成功后访问:http://docker主机地址:5601,显示以下界面
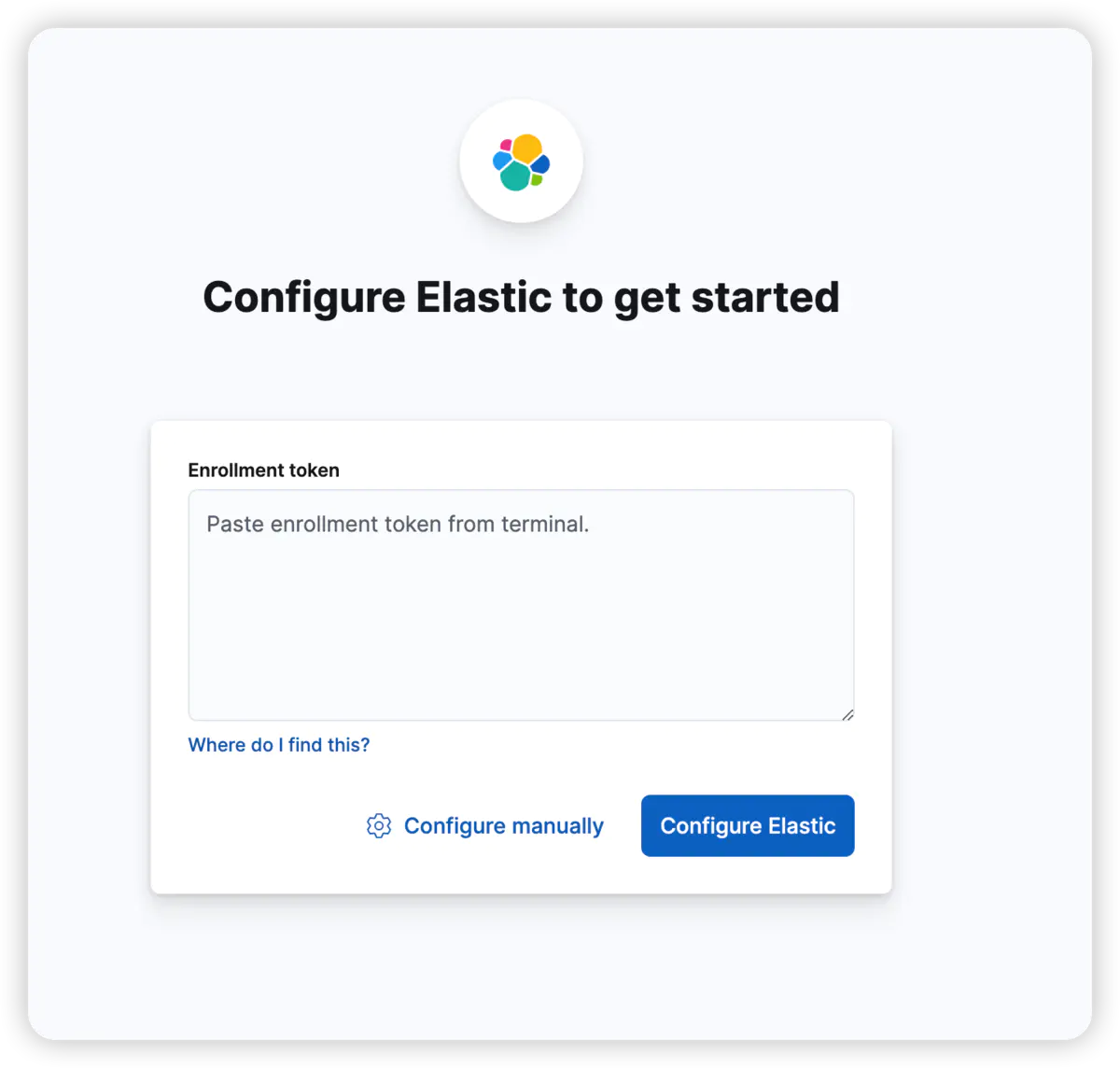
输入上述步骤复制的token,确定,出现输入验证码页面。
此时在启动kibana页面会输出6位数验证码,复制。输入。(如果kibana后台就行,就执行docker logs -ft kibanaId 查看日志)。
进入该页面,表示启动成功。输入上述复制的账号密码,进入。
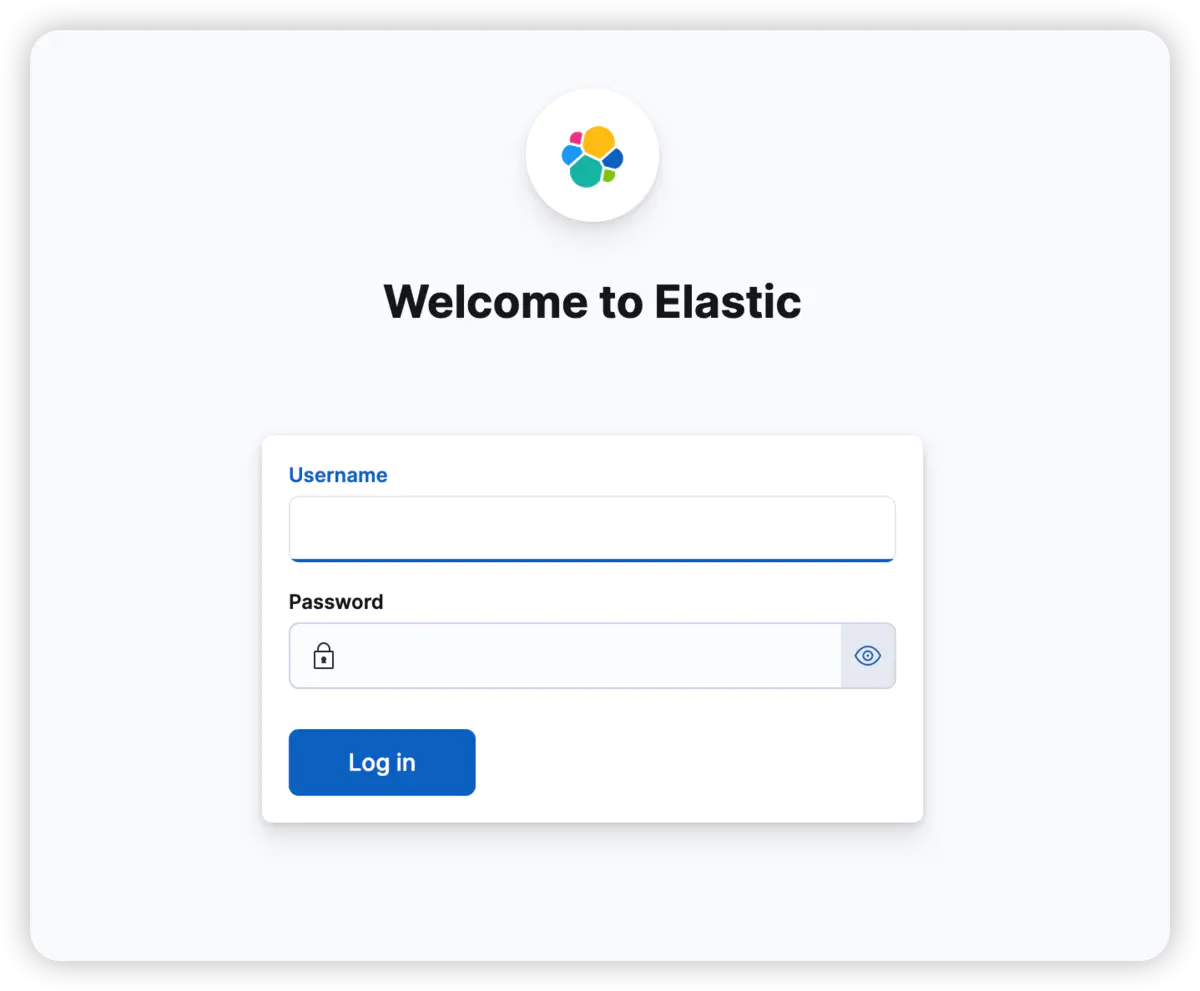
启动成功!!!
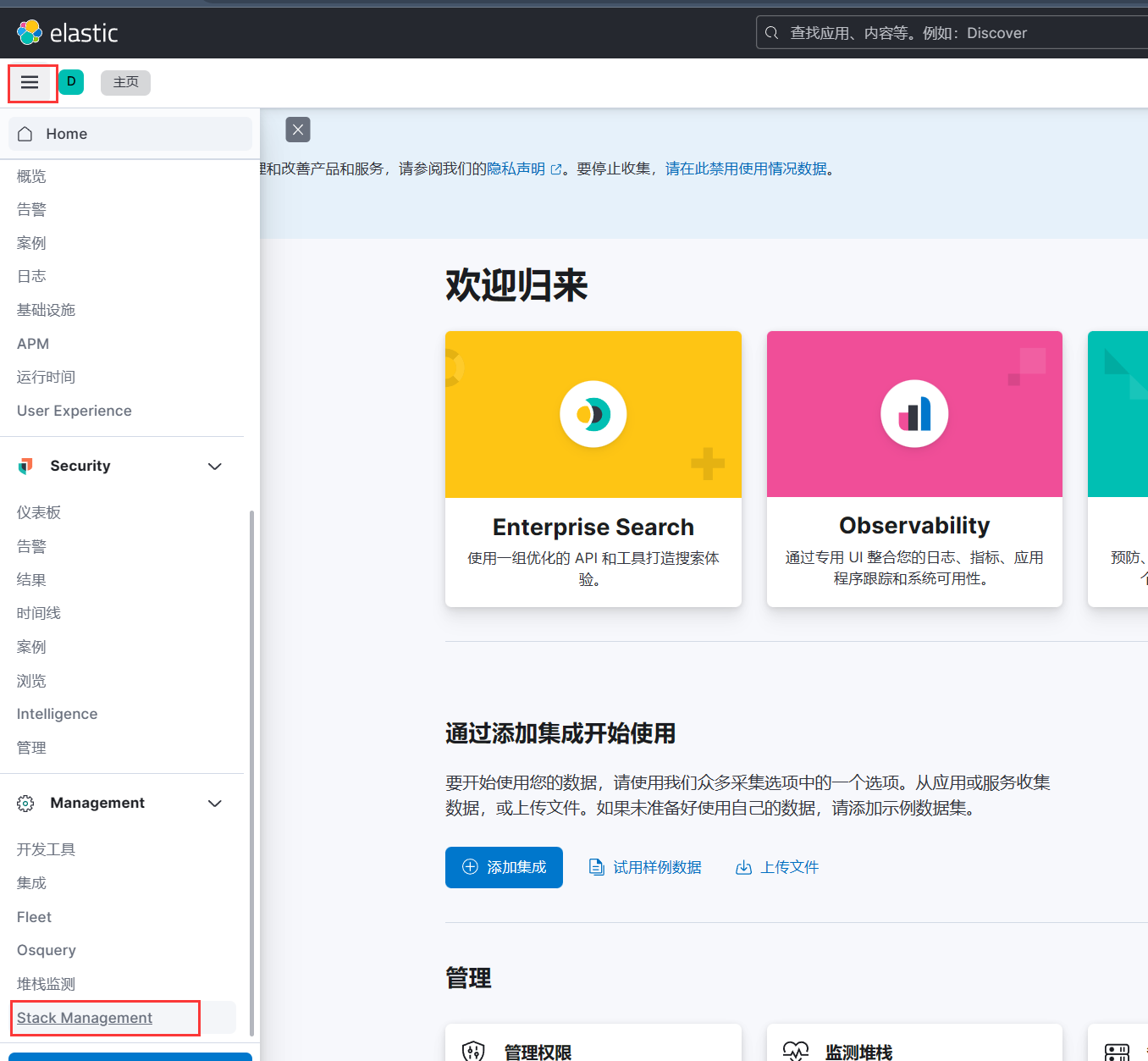
启动kibana后记得去修改密码:进入Stack Management -> Users -> 点击用户名 -> change password
kibana汉化
vi /var/lib/docker/volumes/kbconfig/_data/kibana.yml |
最后一行加入,重启kibana容器(注意冒号后面有空格):
i18n.locale: "zh-CN" |
2.2 配置 Elasticsearch
Elasticsearch 具有良好的默认值,只需要很少的配置。可以使用集群更新设置 API 在运行的集群上更改大多数设置
配置文件应包含特定于节点的设置(如 node.name 和路径),或节点加入群集所需的设置,如 cluster.name 和 network.host。
2.2.1 配置文件位置
Elasticsearch 有三个配置文件:
elasticsearch.yml用于配置 Elasticsearchjvm.options用于配置 Elasticsearch JVM 设置log4j2.properties用于配置 Elasticsearch 日志记录
这些文件位于 config 目录中,其默认位置取决于安装是来自存档发行版(tar.gz 或 zip)还是软件包发行版(Debian 或 RPM 软件包)。
2.2.2 重要的 Elasticsearch 配置
这里后续深挖的时候补上
2.2.3 中文分词插件
es 默认的标准分词器,对于中文是没有很好的兼容的,所以我们对于中文分词要使用更为专业的 IK分词器插件。
下载完成后加压到 plugins 文件夹下,再重启 elasticsearch 即可。
IK 分词器提供了两个分词器算法:
ik_smart:切分力度较大,准确度与查全率不高,但是查询性能较高
ik_max_word:查全率与准确度较高,性能也高,是业务中普遍采用的中文分词器
使用 ik_smart 算法对来进行中文分词,明显会发现与默认分词器的区别;
#分词 |
2.3 基本概念
Elasticsearch是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
索引(indices)----------------------Databases 数据库 |
要注意的是:Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
2.4 DSL
以下 DSL 操作都是再 Kibana 控制台进行操作,REST API,结果以JSON形式返回。
一些基本查询 es 的语句
GET _cluster/health #检查集群节点健康状态 |
查看es中有哪些索引:
GET /_cat/indices?v |
返回一个类似 mysql 一样的数据库表的结构,表头的含义:
| 字段名 | 含义说明 |
|---|---|
| health | green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主节点几个 |
| rep | 从节点几个 |
| docs.count | 文档数 |
| docs.deleted | 文档被删了多少 |
| store.size | 整体占空间大小 |
| pri.store.size | 主节点占 |
2.4.1 Index:索引操作
2.4.1.1 创建索引
PUT /索引名称(必须小写 不能重复创建相同名称的索引) |

参数可选:指定分片及副本。
{ |
2.4.1.2 查询索引是否存在
HEAD 索引名称 (200存在 404不存在) |
2.4.1.3 查询索引
GET /索引名称 #查询单个索引的全部信息 |
2.4.1.4 为索引起别名
# 为索引添加别名 前提是别名并不是一个存在的名称 |
2.4.1.5 修改操作
Elasticsearch 不允许直接修改索引。一个原因是其基于 Lucene 的索引架构。在 Lucene 中,索引是一个只读的数据结构,不能直接修改,而是需要先删除旧索引,然后再创建新索引。这种设计使得 Elasticsearch 可以高效地进行查询和维护索引。
此外,Elasticsearch 允许用户通过 Update API 来更新文档,但是实际上是通过先删除文档,然后再新增文档的方式实现的。所以 修改索引 和 修改文档是不一样的概念。
2.4.1.6 删除索引
DELETE /索引名 |
2.4.1.7 索引模板
我们之前对索引进行一些配置信息设置,但是都是在单个索引上进行设置。如实际开发中,我们可能需要创建不止一个索引,但是每个索引或多或少都有一些共性。比如我们在设计关系型数据库时,一般都会为每个表设计一些常用字段,比如创建实践,更新实践,备注信息等。elasticsearch 在创建索引时,就引入了模板的概念,你可以先设置一些通用的模板,在创建索引的时候,elasticsearch 会先根据你创建的模板对索引进行设置。
创建模板
#创建模板 |
查询模板
GET _template/mytemplate |
删除模板
DELETE _template/mytemplate |
2.4.2 Mapping:映射配置
索引有了,接下来肯定是添加数据。但是,在添加数据之前必须定义映射,但是就算我们不定义映射也可以向索引中插入数据,这是因为 Elasticsearch 的动态映射的特性,能够自动分析出用户插入数据并动态地解映射。
什么是映射?
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
只有配置清楚,Elasticsearch才会帮我们进行索引库的创建(不一定)
2.4.2.1 创建映射字段
PUT /索引 |
类型名称:就是前面将的type的概念,类似于数据库中的不同表
字段名:类似于列名,properties下可以指定许多字段。
每个字段可以有很多属性。例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:分词器,这里使用ik分词器:
ik_max_word或者ik_smart
2.4.2.2 查看映射关系
GET /索引库名/_mapping |
2.4.3Document:文档操作
2.4.3.1 创建文档(索引数据)
_source:源文档信息,所有的数据都在里面。_id:这条文档的唯一标示,与文档自己的id字段没有关联
#指定id的方式 |
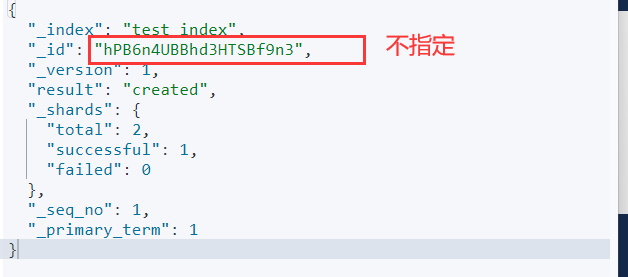
批量增加数据
PUT 索引名/_bulk |
2.4.3.2 查询文档
#查询文档 |
2.4.3.3 修改文档
#修改数据 |
2.4.3.4 删除数据
DELETE 索引/_doc/id |
2.4.4 数据搜索
文档就是 es 中的一条数据,索引数据搜索就是再搜索文档。
2.4.4.1 匹配查询(match)
# 条件查询 match |
这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:
- 例如:
match_all,match,term,range等等
- 例如:
- 查询条件:查询条件会根据类型的不同,写法也有差异。
结果是一个 json串 查询结果字段意义:
- took:查询花费时间,单位是毫秒
- time_out:是否超时
- _shards:分片信息
- hits:搜索结果总览对象
- total:搜索到的总条数
- max_score:所有结果中文档得分的最高分
- hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
- _index:索引库
- _id:文档id
- _score:文档得分
- _source:文档的源数据
我们存储到 es 的文档,如果字段类型是 text 的,将会被分词存储(分词规则由分词器指定)。
match:分词匹配,会将所给匹配的字段值,进行分词再进行匹配。如,zhang san 可能会分成 zhang 和 san 分别匹配(模糊匹配),如果 es 中没有 zhang 或者 san 的数据就无法匹配的上。
term:不分词匹配,会将所给匹配的字段值看作一个整体。如,zhang san 就不会才分,而是将 zhang san 看作一个整体来进行匹配(模糊匹配),如果 es 中没有 zhang san 的数据就无法匹配的上。
要注意 es 是会对存储数据的 text 类型的字段进行分词存储的。
# 对查询结果的字段进行限制 |
子属性匹配
GET 索引名/_search |
2.4.4.2 多条件组合查询(bool)
布尔查询又叫组合查询
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
#组合多个条件 or |
注意:一个组合查询里面只能出现一种组合,不能混用
2.4.4.3 词条查询(term)
term 查询被用于精确值匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串。
GET 索引/_search |
2.4.4.4 排序后查询(sort)
#排序后查询 |
2.4.4.5 分页查询(page-from/size)
#分页查询 |
2.4.4.6 返回查询(range)
range 查询找出那些落在指定区间内的数字或者时间
GET 索引词/_search |
range`查询允许以下字符:
| 操作符 | 说明 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
2.4.4.6 过滤(filter)
所有的查询都会影响到文档的评分及排名。如果我们需要在查询结果中进行过滤,并且不希望过滤条件影响评分,那么就不要把过滤条件作为查询条件来用。而是使用filter方式:
GET 索引名/_search |
注意:filter中还可以再次进行bool组合条件过滤。
2.4.4.7 高亮(highlight)
发现:高亮的本质是给关键字添加了标签,在前端再给该标签添加样式即可。
GET 索引/_search |
fields:高亮字段
pre_tags:前置标签
post_tags:后置标签
2.4.4.8 结果过滤(_source)
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,可以添加_source的过滤
GET 索引/_search |
2.4.5 聚合(aggregations)
2.4.5.1 基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个桶,例如我们根据国籍对人划分,可以得到中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
Elasticsearch中提供的划分桶的方式有很多:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
- ……
bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为度量
比较常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同时返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前几
- Value Count Aggregation:求总数
- ……
2.4.5.2 聚合为桶
根据字段来划分桶(分组)
#分组查询 |
- size: 查询条数,这里设置为0,因为我们不关心搜索到的数据,只关心聚合结果,提高效率
- aggs:声明这是一个聚合查询,是aggregations的缩写
- ageGroup:给这次聚合起一个名字,任意。
- terms:划分桶的方式,这里是根据词条划分
- field:划分桶的字段
- terms:划分桶的方式,这里是根据词条划分
- ageGroup:给这次聚合起一个名字,任意。
聚合查询可以类比 Mysql 的方式
按年龄排序获取前3名
#按年龄排序获取前3名 |
2.4.5.3 桶内度量
前面的例子告诉我们每个桶里面的文档数量,这很有用。 但通常,我们的应用需要提供更复杂的文档度量。 例如,每种品牌手机的平均价格是多少?
因此,我们需要告诉Elasticsearch使用哪个字段,使用何种度量方式进行运算,这些信息要嵌套在桶内,度量的运算会基于桶内的文档进行
现在,我们为刚刚的聚合结果添加 求年龄平均值的度量:
#先分组再求和 |
- aggs:我们在上一个aggs(brands)中添加新的aggs。可见
度量也是一个聚合 - avg_price:聚合的名称
- ageSum:度量的类型,这里是求平均值
- field:度量运算的字段
可以看到每个桶中都有自己的ageSum字段,这是度量聚合的结果
2.4.5.4 桶内嵌套桶
刚刚的案例中,我们在桶内嵌套度量运算。事实上桶不仅可以嵌套运算, 还可以再嵌套其它桶。也就是说在每个分组中,再分更多组。
比如:我们想统计每个品牌都生产了那些产品,按照attr.category.keyword字段再进行分桶
GET 索引名/_search |
- 我们可以看到,新的聚合
categorys被嵌套在原来每一个brands的桶中。 - 每个品牌下面都根据
attr.category.keyword字段进行了分组
2.5 文档评分机制
经过前面的查询我们已经发现了,检索的返回数据中每条数据会带上一个 _score 字段,这个分值代表匹配度,匹配度越高,分值越高。
分支计算公式。再查询的uri上带上 explain = true,返回结果会显示计算公式。Lucene 和 ES 的得分机制是一个基于词频和逆文档词频的公式,简称为 TF-IDF 公式
GET 索引名/_search?explain=true |
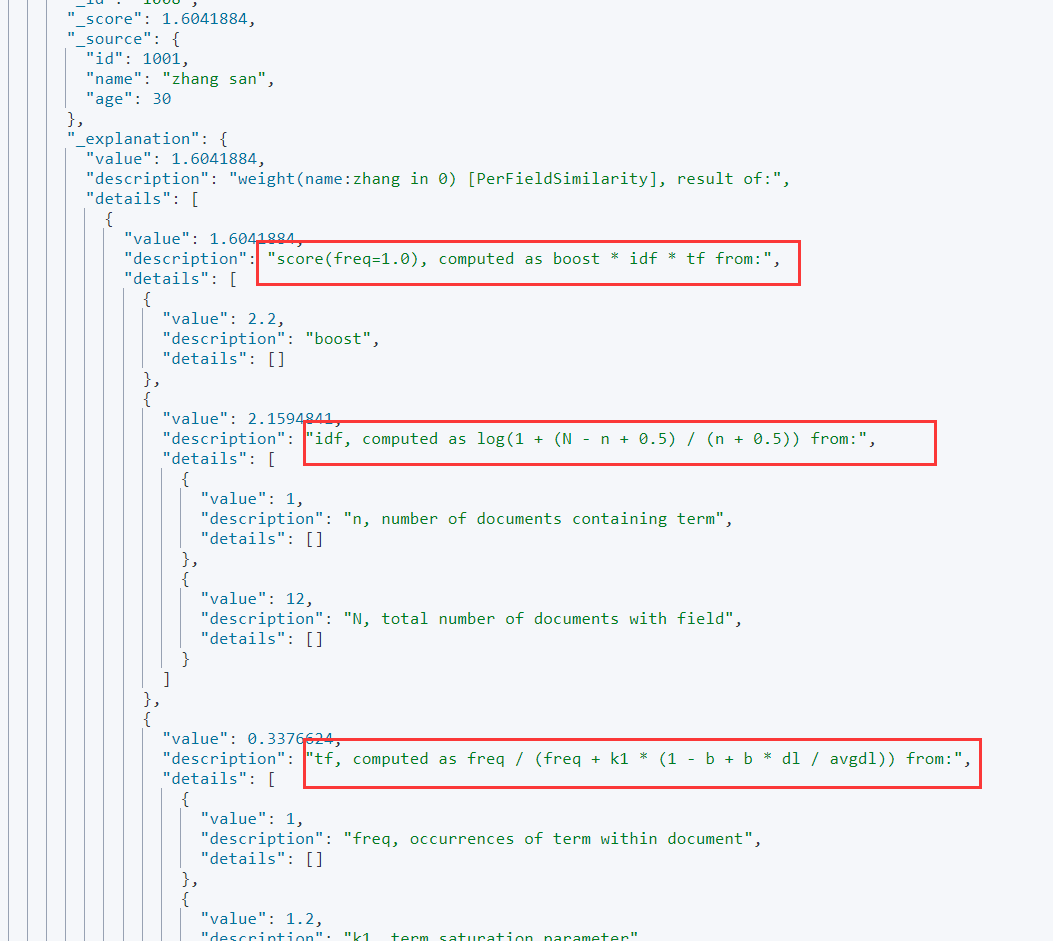
TF(词频)
Term Frequency:搜索文本中的各个词条(term)在查询中出现了多少次。
IDF(逆文档频率)
Inverse Document Frequency:搜索文本中的各个词条(term)在整个索引的所有文档中的出现了多少次,出现次数越多,说明越不重要,也就越不相关,得分就越低。
3. 整合
目前市面上有两类客户端
一类是TransportClient 为代表的ES原生客户端,不能执行原生dsl语句必须使用它的Java api方法。
另外一种是以Rest Api为主的missing client,最典型的就是jest。 这种客户端可以直接使用dsl语句拼成的字符串,直接传给服务端,然后返回json字符串再解析。
两种方式各有优劣,但是最近elasticsearch官网,宣布计划在7.0以后的版本中废除TransportClient。以RestClient为主。
由于原生的Elasticsearch客户端API非常麻烦。但Spring为我们提供的集成的套件:Spring Data Elasticsearch。可以让我们更方便地操作 Elasticsearch。
3.1 SpringData-Elasticsearch
这里因为还没有打算使用 JDK 17 所以没有用 SpringBoot 3.0,并且因为兼容问题,我把Elasticsearch 的版本降低至了 7.17.3
3.1.1 导入依赖
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.7.5</version>
</dependency>
3.1.2 配置
spring: |
3.1.3 实体类
|
Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
@Document作用在类,标记实体类为文档对象,一般有四个属性- indexName:对应索引库名称
- type:对应在索引库中的类型
- shards:分片数量,默认5
- replicas:副本数量,默认1
@Id作用在成员变量,标记一个字段作为id主键@Field作用在成员变量,标记为文档的字段,并指定字段映射属性:- type:字段类型,取值是枚举:FieldType
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称:ik_max_word
3.1.4 创建索引及映射
因为配置了实体类,指定了索引、映射和一些配置,所以在 SpringBoot 启动加载 Bean 时就会自动创建索引。
// ElasticsearchRestTemplate是RestHighLevel客户端 |
删除索引
|
3.1.5 Repository文档操作
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。
类似于 Mybatis-plus 的 BaseMapper,但Spring Data 更为强大。
|
通过这个 dao 我们就可以对索引内的文档进行各种基本的 CRUD 功能了。
|
3.1.6 新增
|
修改和新增是同一个接口,区分的依据就是id,这一点跟我们在页面发起PUT请求是类似的。
3.1.7 修改
|
3.1.8 删除
|
3.2.1 查询
3.2.1.1 基本查询
查询一个:
|
查询全部:
|
3.2.1.2 条件查询
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
只要我们在 Repository 接口中写上方法签名,不需要实现,Spring Data 就看也自动帮助实现功能。
当然,方法名称要符合一定的约定:
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And |
findByNameAndPrice |
{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or |
findByNameOrPrice |
{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is |
findByName |
{"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not |
findByNameNot |
{"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between |
findByPriceBetween |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual |
findByPriceLessThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual |
findByPriceGreaterThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before |
findByPriceBefore |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After |
findByPriceAfter |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like |
findByNameLike |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith |
findByNameStartingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith |
findByNameEndingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing |
findByNameContaining |
{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In |
findByNameIn(Collection<String>names) |
{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn |
findByNameNotIn(Collection<String>names) |
{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{"bool" : {"must" : {"field" : {"available" : true}}}} |
False |
findByAvailableFalse |
{"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy |
findByAvailableTrueOrderByNameDesc |
{"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
准备一组数据:
|
在UserRepository中定义一个方法:
第一种写法:
|
第二种写法:这种适合复杂查询
|
3.2.1.3 自定义查询
|
NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
Page<item>:默认是分页查询,因此返回的是一个分页的结果对象,包含属性:
- totalElements:总条数
- totalPages:总页数
- Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
除上述之外,SpringData-Elasticsearch 还有其他强大的功能,还有 API 这里并没有展示,可以在官网查看(https://docs.spring.io/spring-data/elasticsearch/docs/4.4.6/reference/html/#repositories)

