布隆过滤器
布隆过滤器(BloomFilter)
引言
我们经常会将一部分数据放在redis等缓存中,比如产品信息。这样有查询请求进来,我们就可以根据产品id直接去缓存中取得数据,如果没有再去读取数据库,再将数据放入缓存,再返回数据,大大减少了访问数据库的次数,这是提升性能最普遍的方式。
但是如果现在有大量的请求进来,而且都在请求一个不存在的id,就会导致大量的请求去访问数据库,而数据库对于不存在的id是需要遍历整个表之后返回一个null的,这样大量的请求访问数据库,很大可能导致数据库宕机,
这时我们急需一个解决方案,在无效id访问缓存的之前就判断该id不存在。布隆过滤器就是一个很好的选择。
背景及意义
布隆过滤器(英语:Bloom Filter)是 1970 年由一个叫做布隆的老哥提出的。它底层实际上是一个很长的bit数组和一系列随机映射函数。主要用于判断一个元素是否在一个集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景(比如缓存场景),一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,这个时候,布隆过滤器(Bloom Filter)就应运而生。
算法描述
布隆过滤器的数据结构如图所示
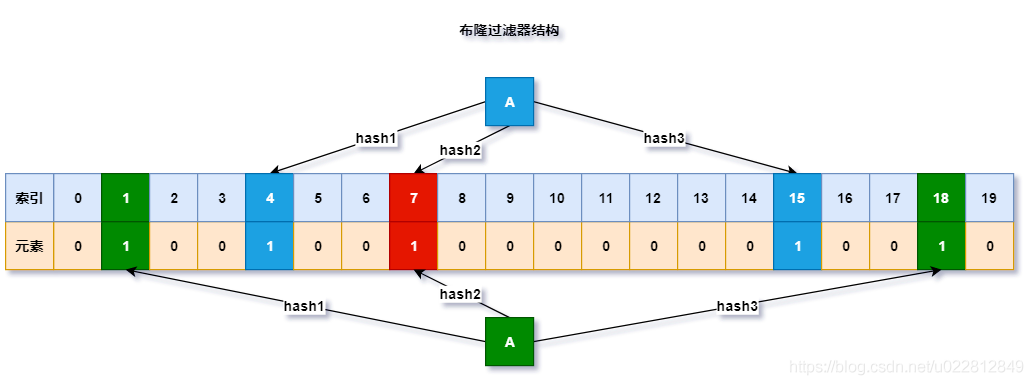
可以发现最底层是一个bit数组,通过一系列hash算法将元素映射到bit数组上。下面我们来介绍一下布隆过滤器(Bloom Filter)的算法。
当一个元素加入到布隆过滤器中的时候,会进行如下操作。
- 使用布隆过滤器中的hash函数对元素值进行计算,得到元素的hash值(有几个hash函数获得几个hash值)。
- 根据得到的hash值,在bit数组中把对应下标的值由0置为1.
当我们需要判断一个元素是否存在于布隆过滤器中时,会进行如下操作。
- 对给定元素再次进行相同的hash计算;
- 得到值之后判断bit数组中的每个元素是否都为1,如果值为1,那么说明整个值在布隆过滤器中,如果存在一个值不为1,说明该元素不在过滤器中。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
因为hash冲突的缘故,不同元素通过hash计算可能会得到相同的hash值;所以布隆过滤器计算得到一个元素是否存在时,可能会出现误判,但是如果布隆过滤器判断一个元素不存在,那么该元素一定不存在。
对于布隆过滤器的误判的情况,可以通过增加bit数组的大小或者调整hash函数来减小概率。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
优缺点
优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白
名单,存储可能会误判的数据)- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
应用场景
- 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
- 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
- 钓鱼网站识别
- 秒杀系统:查看用户是否重复购买
算法实现
Java
Bloom-Filter.java
package org.dyw.bloomFilter; |



