《Java并发编程之美》读书笔记
《Java并发编程之美》读书笔记
收到pymjl大佬《Java并发编程之美》读书笔记的启发,于是决定自己也写一个,帮助自己理解和回顾
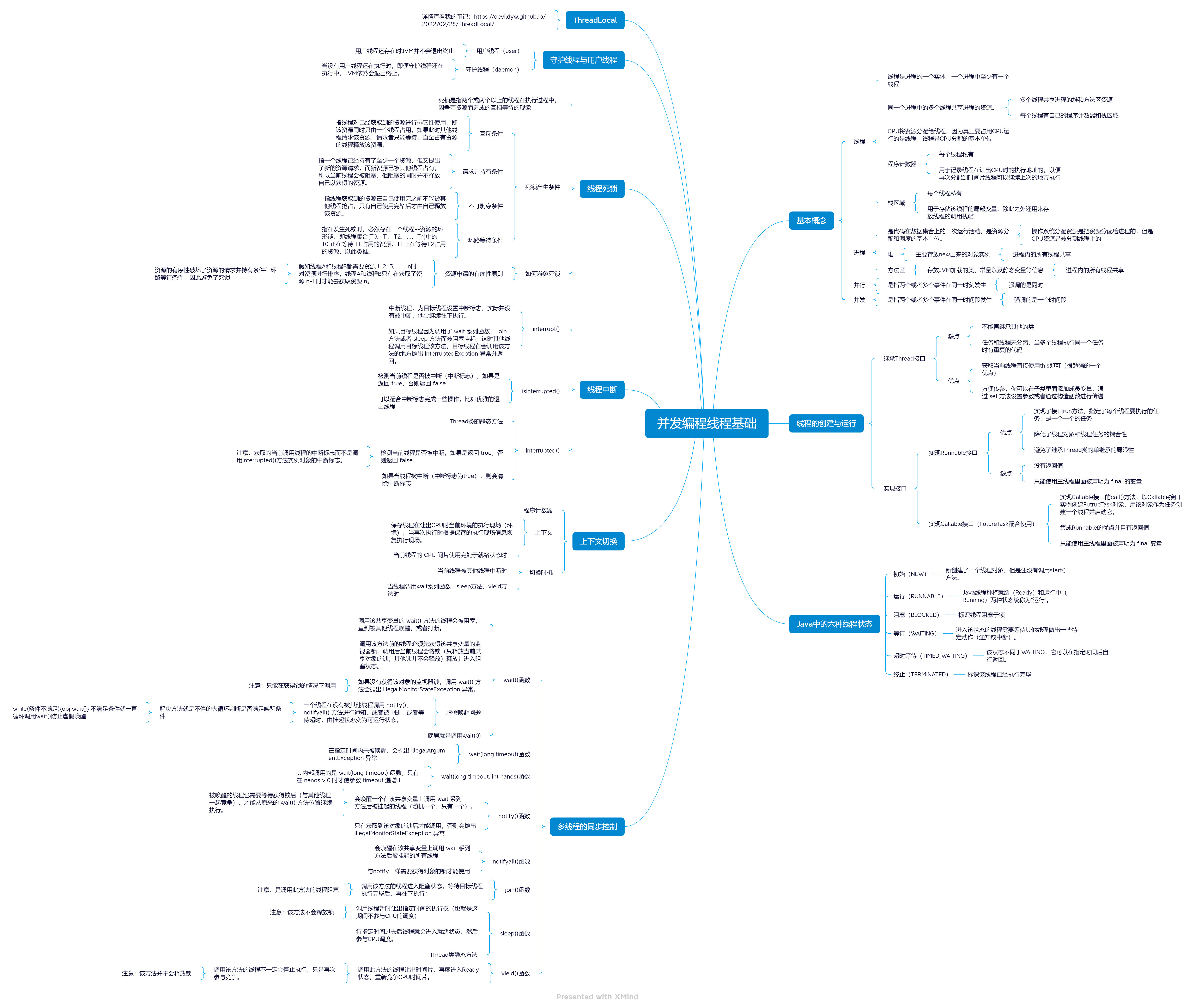
第一章 并发编程线程基础
第二章 并发编程其他基础知识
第三章 Java并发包中ThreadLocalRandom类原理剖析
ThreadLocalRandom类是JDK7 在JUC包下新增的随机数生成器,它弥补了 Random类在多线程下的缺陷。
Random 类及其局限性
先看看 java.util.Random 的使用方法。
public class RandomTest { |
随机数的生成需要一个默认的种子,这个种子其实是一个 long 类型的数字,你可以在创建 Random 对象时通过构造函数指定,如果不指定则在默认构造函数内部生成一个默认的值。有了默认的种子后,如何生成随机数呢?
接下来我们来看看获取随机数的方法 nextInt(int bound)
public int nextInt(int bound) { |
随机数的生成需要两个步骤:
- 首先根据老的种子生成新的种子。
- 然后根据新的种子来计算新的随机数。
在单线程情况下每次调用 nextInt 都是根据老的种子计算出新的种子,这是可以保证随机数产生的随机性的。但是多线程下多个线程可能都拿同一个老种子去生成新的种子,由于通过种子计算随机数的步骤时固定的,所以会导致多个线程产生相同的随机值。
要保证多线程下的可以生成不同的随机值,必须要保证根据老种子生成新种子的原子性。
Random 函数使用了一个原子变量达到了这个效果,在创建 Random 对象时初始化的种子就被保存到了种子原子变量里面。
next()
protected int next(int bits) { |
每个 Random 实例里面都有一个原子性的种子变量用来记录当前的种子值,当要生成新的随机数时需要根据当前种子计算新的种子并更新回原子变量,在多线程下使用 Random 实例生成随机数时,当多个线程同时计算随机数来计算新的种子时,多个线程会竞争同一个原子变量的更新操作,由于原子变量的更新操作是
CAS操作,同时只有一个线程会成功,所以会导致大量线程进行自旋重试,这会降低并发性能,所以ThreadLocalRandom应运而生。
ThreadLocalRandom
为了弥补多线程高并发情况下 Random 的性能缺陷,在 JUC 包下新增了 ThreadLocalRandom 类。
使用
public class ThreadLocalRandomTest { |
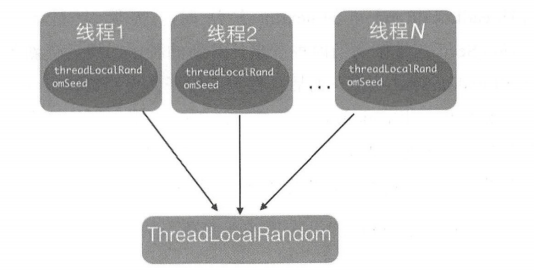
与 ThreadLocal 通过让每一个线程复制一份变量,使得在每个线程对变量进行操作时实际是操作自己本地内存里面的副本,来避免对共享变量进行同步的方法相似,ThreadLocalRandom 也是这个原理。
Random的缺点是多个线程会使用同一个原子性种子变量,从而导致了对原子变量更新的竞争。

如果每一个线程都维护一个种子变量,那么每个线程生成随机数时都根据自己老的种子计算新的种子,并使用新种子更新老的种子,再根据新种子计算随机数,就不会存在竞争问题了,大大提高并发性能。
源码分析
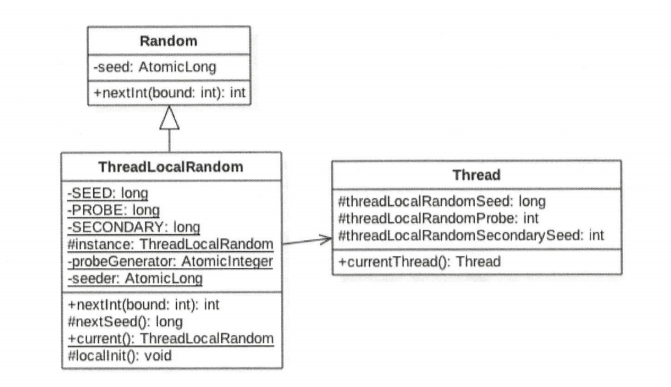
由图中可以看出 ThreadLocalRandom 类继承了 Random类 并重写了 nextInt 方法,在ThreadLocalRandom 类中并没有使用继承自 Random 类的原子性种子变量。
在 TheadLocalRandom 中并没有存放具体的种子,具体的种子存放在具体的调用线程的 threadLocalRandomSeed 变量里面。ThreadLocalRandom 类似于 ThreadLocal 类,就是个工具类。当线程调用 ThreadLocalRandom 的 current 方法时,ThreadLocalRandom 负责初始化调用线程的 threadLocalRandomSeed 变量,也就是初始化种子。

当调用 ThreadLocalRandom 的 nextInt 方法时,实际上是获取当前线程的 threadLocalRandomSeed 变量,再根据新种子并使用具体方法计算随机数。
threadLocalRandomSeed 变量就是 Thread 类里面的一个普通 long 型变量,他并不是原子性变量。(因为该变量是线程私有的,所以根本不用使用原子性变量)
变量 instance 是
ThreadLocalRandom的一个实例,该变量是 static 的。当多线程通过ThreadLocalRandom的 current 方法获取ThreadLocalRandom的实例时,其实获取的是同一个实例。但是由于具体的种子里面是存放在线程里面的,所以在ThreadLocalRandom的实例里面只包含与线程无关的通用算法,所以它是线程安全的。

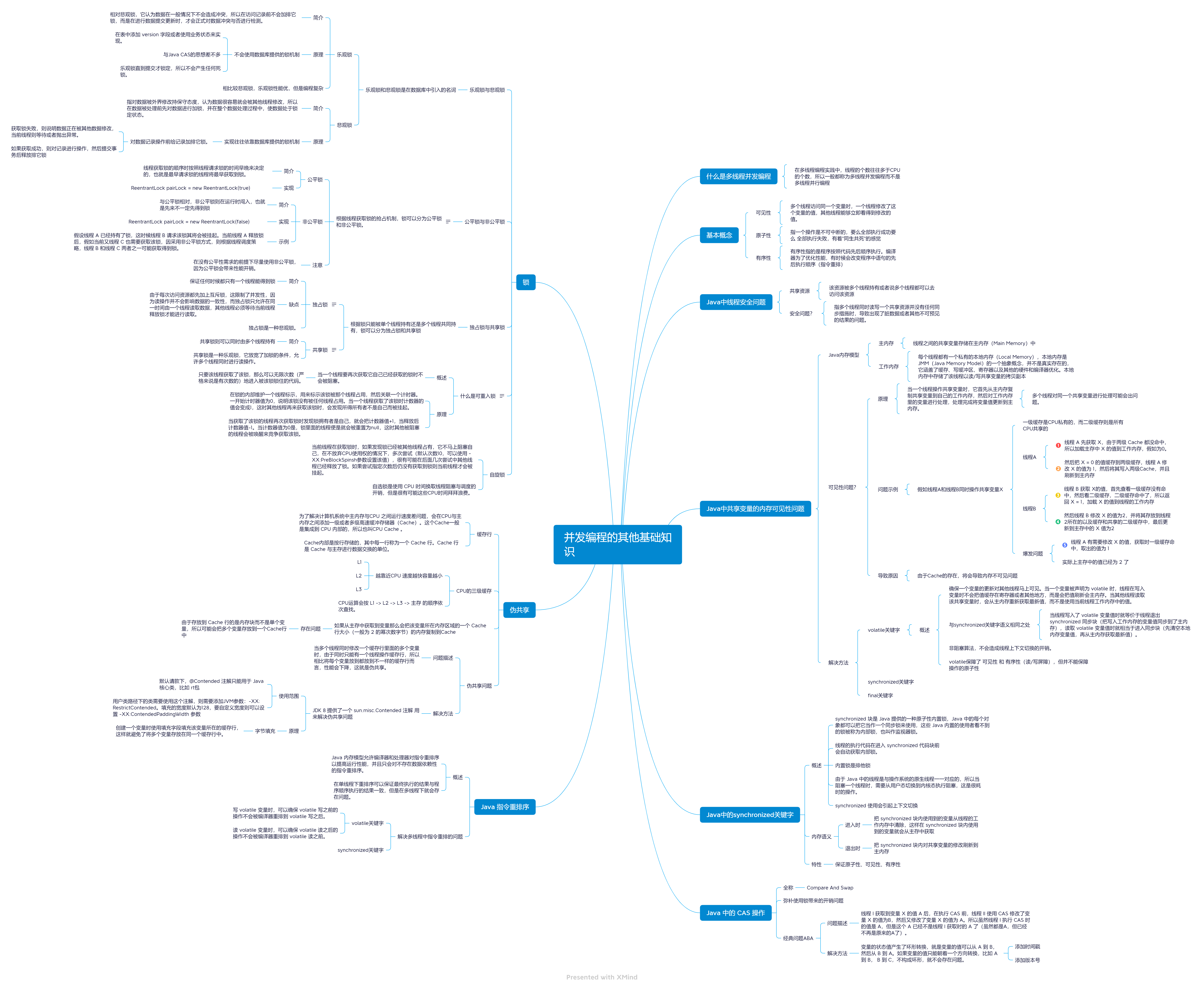
第四章 Java并发包中原子操作类原理剖析
JUC包提供了一系列的原子性操作类,这些类都是使用非阻塞算法CAS实现的,相比使用锁实现原子性操作这在性能上有很大提高。由于原子性操作类的原理都大致相同,所以这里只介绍几个简单类的原理。
原子变量操作类
对于 JUC 并发包中的 AtomicInteger、AtomicLong 和 AtomicBoolean 等原子性操作类,它们原理类似。这里单独拿出 AtomicLong 讲解。
AtomicLong 是原子性递增或者递减类,其内部使用 Unsafe 来实现。
AtomicLong 源码
public class AtomicLong extends Number implements java.io.Serializable { |
之所以可以通过
Unsafe.getUnsafe()方法获取到 Unsafe 类的实例,是因为AtomicLong类也是在rt.jar包下面的,**AtomicLong类就是通过BootStrap类加载器进行加载的。**
实际变量值(具体存放计数的变量)被声明为 volatile 的,这是为了保证在多线程下保证内存可见性。
AtomicLong 中的主要函数
- 递增和递减操作代码
//调用unsafe方法,原子性设置value值为原始值+1,返回值为递增后的值 |
如上代码内部都是通过 Unsafe 的 getAndAddLong 方法来实现操作,这个函数是个原子性操作,这里第一个参数是 AtomicLong 实例的引用,第二个参数是 value 变量在 AtomicLong 中的偏移值,第三个变量是要设置的第二个变量要改变的值。
getAndAddLong 方法在 JDK 7 中的实现逻辑是通过自旋锁进行更新。
public final long getAndIncrement(){ |
而在 JDK 8 将改代码转移到了 unsafe.getAndAddLong 中
public final long getAndAddLong(Object o, long offset, long delta) { |
将自旋锁的操作内置到 Unsafe 类的方法中,之所以内置应该是考虑到这个函数在其他地方也会用到,而内置可以提高复用性。
public final boolean compareAndSet(long expect, long update)方法
public final boolean compareAndSet(long expect, long update) { |
内部还是调用了 unsafe.compareAndSwapLong 方法。如果原子变量中的 偏移量为valueOffset的 value 值等于expect,则使用 update 值更新该值并返回 true,否则返回false。
案例:统计 0 的个数
public class AtomicTest { |
输出结果为:

在没有使用原子类的请款下,实现计数器需要使用一定的同步措施,比如使用synchronized 关键字等,但是这些都是阻塞算法,对性能有一定的损耗,而原子操作类都是用 CAS 非阻塞算法,性能更好。
但是在高并发情况下 AtomicLong 还会存在个性能问题。JDK 8 提供了一个在高并发下性能更好的 LongAddr 类
JDK 8 新增的原子操作类 LongAddr
使用 AtomicLong 时,在高并发下大量线程会同时竞争更新同一个原子变量,但是由于同时只有一个线程的 CAS 操作会成功,这就造成了大量线程竞争失败后,会通过无限循环不断进行自旋尝试 CAS 操作,而这会白白浪费 CPU 资源。
JDK 8 为了弥补这个缺点,LongAdder 应运而生。
既然
AtomicLong的性能瓶颈是过多线程同时去竞争一个变量的更新而产生的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源。
AtomicLong

LongAdder
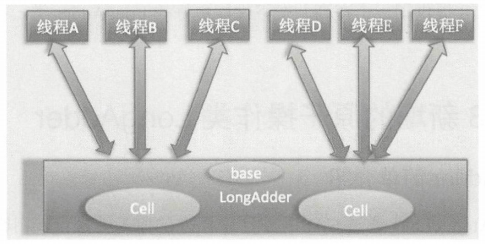
使用
LongAdder时,是在内部维护了多个 Cell 变量,每个 Cell 里面有一个初始值为 0 的 long 型变量,这样,在同等并发量的情况下,争夺单个变量更新操作的线程量会减少,这变相地减少了争夺共享资源的并发量。多个线程在争夺同一个 Cell 原子变量时如果失败了,它并不是在当前 Cell 变量上一直
CAS重试,而是尝试在其他 Cell 的变量上进行CAS尝试,这个改变增加了当前线程重试CAS成功的可能性。在获取
LongAdder当前值时,是把所有 Cell 变量的 value 值累加后再加上 base 返回的。
LongAdder 维护了一个延迟初始化的原子性更新数组(默认情况下 Cell 数组是 null)和一个基值变量 base。 由于 Cells 占用的内存是相对比较大的,所以一开始并不创建它,而是在需要时创建,也就是惰性加载
当一开始判断 Cell 数组是 null 并且并发线程较少时,所有的累加操作都是对 base 变量进行的。保持 Cell 数组的大小为 2 的 N 次方,在初始化时 Cell 数组中的 Cell 个数为2,数组里面的变量实体是 Cell 类型。Cell 类型是
AtomicLong的一个改进,用来减少缓存的争用,也就是解决伪共享问题。对于大多数孤立的多个原子操作进行字节填充是浪费的,因为原子操作都是无规律地分散在内存中的(也就是说多个原子性变量的内存地址是不连续的),多个原子变量被放入同一个缓存行的可能性很小。但是原子性数组元素的内存地址是连续的,所以数组内的多个元素能经常共享缓存行,因此这里使用
@sun.misc.Contended注解 对 Cell 类进行字节填充,这防止了数组中多个元素共享一个缓存行,在性能上是一个提升。
LongAdder 源码分析
LongAdder 的类图结构:
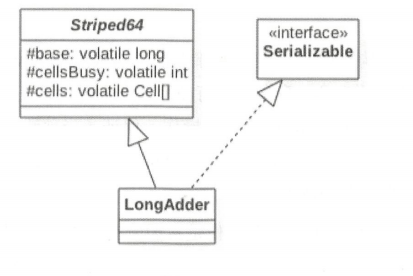
由图可知 LongAdder 类继承自 Striped64 类,在 Striped64 内部维护着三个变量。**LongAdder 的真实值其实是 base 的值于 Cell 数组里面所有 Cell 元素中的value 的值累加,base 是个基础值,默认为0。cellsBusy 用来实现自旋锁,状态值只有 0 和 1 ,当创建 Cell 元素,扩容 Cell 数组或者初始化 Cell 数组时,使用 CAS 操作该变量来保证同一时刻只有一个线程可以进行其中之一的操作。**
Cell 的构造
.misc.Contended static final class Cell { |
Cell的构造很简单,其内部维护一个被声明为 volatile 的变量,这里声明为 volatile 是因为线程操作 value 变量时没有使用锁,为了保证变量的内存可见性这里将其声明为 volatile 的。cas函数通过CAS操作,保证了当前线程更新时被分配的 Cell 元素中 value 值的原子性。- Cell 类 使用
@sun.misc.Contended修饰是为了避免伪共享。
long sum()返回当前的值,内部操作时累加所有 Cell 内部的 value 值后再累加 base。
public long sum() { |
由于计算总和时没有对 Cell 数组进行枷锁,所以在累加过程中可能有其他线程对 Cell 中值进行修改,也有可能对数组进行了扩容,所以 sum 返回的值并不是非常精确,其返回值并不是一个调用 sum 方法时的原子快照值。
void reset()重置操作,如下代码把 base 置为 0,如果 Cell 数组有元素,则元素值被重置为 0。
public void reset() { |
long sumThenReset()是sum的改造版本,在使用 sum 累加对应的 Cell 值后,把当前 Cell 的值重置为 0,base 重置为 0。这样当多线程调用该方法时会有问题,比如考虑第一个调用线程清空 Cell 的值,则后一个线程调用时累加的都是 0 值。
public long sumThenReset() { |
long longValue()等价于sum()void add(long x)
public void add(long x) { |
LongAccumulator 类
LongAdder 类是 LongAccumulator 的一个特例,LongAccumulator 比 LongAdder 的功能更强大。例如如下的构造函数,其中 accumulatorFunction 是一个双目运算器接口,其根据输入的两个参数返回一个计算值,identity 则是 LongAccumulator 累加器的初始值(base的值)。
public LongAccumulator(LongBinaryOperator accumulatorFunction, |
LongAccumulator 相比于 LongAdder,可以为累加器提供非 0 的初始值,后者只能提供默认的 0 值。另外,**LongAccumulator 还可以指定累加规则**,只需要在构造 LongAccumulator 时传入自定义的双目运算器即可,LongAdder 则内置累加的规则。
public void accumulate(long x) { |
第五章 Java 并发包中并发 List 源码剖析
简介
并发包中的并发 List 只有 CopyOnWriteArrayList。CopyOnWriteArrayList 是一个线程安全的 ArrayList,对其进行的修改操作都是在底层的一个复制的数组(快照)上进行的,也就是使用了写时复制策略。
CopyOnWriteArrayList 类图结构如下:

由 CopyOnWriteArrayList 类图可知,每个 CopyOnWriteArrayList 对象里面有一个 array 数组对象用来存放具体元素,ReentrantLock 独占锁对象用来保证同时只有一个线程对 array 进行修改。
ReentrantLock是独占锁,同时只有一个线程可以获取,后面会专门进行介绍。
如果让我们自己做一个写时复制的线程安全的 list 我们会怎么做,有哪些点需要考虑?
- 何时初始化 list,初始化的 list 元素的个数为多少,list 是有限大小吗?
- 如何保证线程安全,比如多个线程读写时如何保证是线程安全的?
- 如何保证使用迭代器遍历 list 时的数据一致性?
主要方法源码解析
初始化
无参构造
public CopyOnWriteArrayList() { |
有参构造
//创建一个list,其内部元素是入参toCopyIn的副本 |
添加元素
CopyOnWriteArrayList 中用来添加元素的函数由 add(E e)、 add(int index, E element)、 addIfAbsent(E e) 和 addAllAbsent(Collection<? extends E> c) 等,他们原理类似,这里单拿 add(E e) 为例来讲解。
public boolean add(E e) { |
进入代码首先会执行代码去获取独占锁,如果多个线程都调用 add 方法则只有一个线程会获取到该锁,其他线程会被阻塞挂起知道锁被释放(避免了该线程在添加元素的过程中不会对 array 进行修改)。
紧接着获取 array,然后复制 array 到一个新数组(从这里可以知道新数组的大小是原来数组大小增加 1,所以 CopyOnWriteArrayList 是无界 list),并把新增的元素添加到新数组。
最后使用新数组替换原数组,并在返回前释放锁。
由于加了锁,所以整个
add过程是一个原子性操作。注意:在添加元素时,首先复制了一个快照,然后在快照上进行添加,而不是在原来数组上进行,最后将快照替换原来数组。
获取指定位置元素
使用 E get(int index) 获取下标为 index 的元素,如果元素不存在则抛出 IndexOutOfBoundsException 异常。
private E get(Object[] a, int index) { |
如上代码,当线程调用 get() 方法获取指定位置的元素时,分两步走,首先获取 array 数组(这里命名为步骤 A),然后通过下标访问指定位置的元素(这里命名为步骤 B),这是两步操作,但是在整个过程中并没有进行加锁同步。
由于并没有加锁,这就可能导致在线程执行完 步骤 A 后执行步骤 B 前,另一个线程进行了 remove 操作。 remove 操作首先会获取独占锁,然后进行写时复制操作(也就是复制一份当前 array 数组),然后在复制的数组里面删除元素,之后让 array 指向复制的数组。而这个时候 array 之前之前的数组引用计数为 1 而不是 0,是因为我们调用 get 方法的线程还在使用它,这时候执行步骤 B,步骤 B 操作的数组时线程 y 删除元素之前的数组。
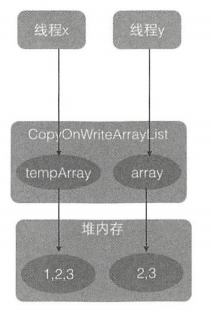
虽然线程 y 已经修改了 index 处的元素,但是线程 x 的步骤 B 还是会返回 index 处的元素,这其实就是写时复制策略产生的弱一致性问题。
修改指定元素
使用 E set(int index, E element) 修改 list 中指定元素的值,如果指定位置的元素不存在则抛出 IndexOutOfBoundsException 异常。
public E set(int index, E element) { |
如上代码,进入代码首先获取独占锁,从而阻止了其他线程对 array 数组进行修改,然后获取当前数组,并调用 get 方法获取指定位置的元素,如果指定位置的元素值与新值不一致则创建新数组并复制元素,然后在新数组的上修改指定位置的元素值并设置新数组到 array。如果指定位置的元素值与新值一样,则为了保证 volatile 语义,还是需要重新设置 array,虽然 array 的内容并没有改变。
删除元素
删除 list 里面指定的元素,可以使用 E remove(int index)、boolean remove(Object o) 和 boolean remove(Object o, Object[] snapshot, int index) 等方法,他们原理一样。
单独讲解 reomve(int index)
public E remove(int index) { |
如上代码,首先获取独占锁以保证删除数据期间其他线程不能对 array 进行修改,然后获取数组中要被删除的元素,并把剩余的元素复制到新数组,之后再用新数组替换原来的数组。
弱一致行的迭代器
遍历列表元素可以使用迭代器。迭代器使用不在多说。
下面来看 CopyOnWriteArrayList 中迭代器的弱一致性是怎么回事,所谓弱一致性是指返回迭代器后,其他线程对 list 的增删改对迭代器是不可见的。
CopyOnWriteArrayList 迭代器源码
public Iterator<E> iterator() { |
如上代码,当 CopyOnWriteArrayList 对象调用 iterator() 方法获取迭代器时实际上会返回一个 COWIterator 对象,COWIterator 对象的 snapshot 变量保存了当前 list 的内容,cursor 是遍历 list 时数据的下标。
为什么说snapshot 时list的快照呢?明明是指针传递的引用啊,而不是副本。
如果在该线程使用返回的迭代器遍历元素的过程中,其他线程没有对 list 进行增删改,那么
snapshot本身就是 list 的array,因为它们是引用关系。但是如果在遍历期间其他线程对该 list 进行了增删改,那么snapshot就是快照了,因为增删改后 list 里面的数组被新数组替换了,这时老数组被snapshot引用,这也就说明获取迭代器后,使用迭代器元素时,其他线程对该 list 进行的增删改不可就按,他们他们操作的时两个不同的数组,这就是弱一致性。
示例:
public class ListTest { |
输出结果如下:
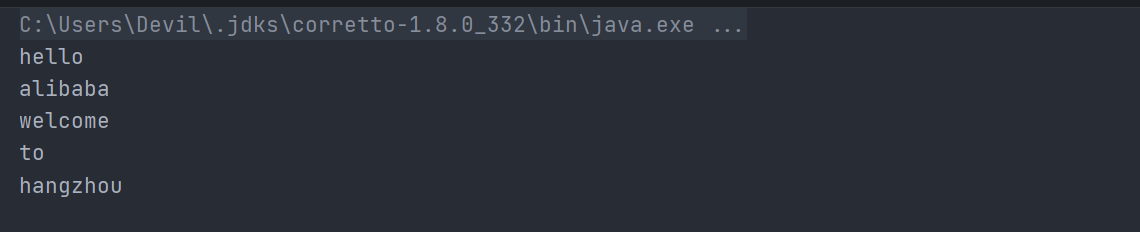
由上可见,主线程在子线程执行完毕后使用获取的迭代器遍历数组元素,从输出结果我们知道,在子线程里面进行的操作一个都没有生效,这就是迭代器弱一致性的体现。需要注意的是,获取迭代器的操作必须在子线程操作之前进行。
第六章 Java并发包中锁原理剖析
LockSupport 工具类
JDK 中的 rt.jar 包里面的 LockSupport 是个工具类,它的主要作用是挂起和唤醒线程,该工具是创建锁和其他同步类的基础。
LockSupport 类与每个使用它的线程都会关联一个许可证,在默认情况下调用 LockSupport 类的方法的线程是不持有许可证的。LockSupport 是使用 Unsafe 实现的。
方法介绍
void park()
如果调用 park() 方法的线程已经拿到了与 LockSupport 关联的许可证,则调用 LockSupport.park() 时会马上返回,否则调用线程会被禁止参与线程的调度,也就是会被阻塞挂起。
public static void park() { |
示例:
|
上述代码里面调用 park() 方法,最终只会输出 begin park!,然后当前线程就会被挂起,这是因为在默认情况下调用线程是不持有许可证的。
在其他线程调用 unpark(Thread thread) 方法并且将当前线程作为参数时,调用 park 方法而被阻塞的线程会返回。另外如果其他线程调用了阻塞线程的 interrupt() 方法,设置了中断标志或者线程被虚假唤醒,则阻塞线程也会返回。所以在调用 park 方法时最好也使用循环条件判断方式。
注意:调用
park()方法而被阻塞的现场被其他线程中断而返回时并不会抛出InterruptedException异常。
void unpark(Thread thread)
当一个线程调用 unpark() 时,如果参数 thread 线程没有持有 thread 与 LockSupport 类关联的许可证,会让线程持有。如果 thread 之前因调用 park() 而被挂起,则调用 unpark 后,该线程会被唤醒。如果 thread 之前没有调用 park() ,则调用 unpark() 方法后,再调用 park() 方法,其会立刻返回。
修改代码如下。
|
该代码会正常输出。
示例
|
park 方法返回时不会告诉你因何种原因返回,所以调用者需要根据之前调用 park 方法的原因,再次检查条件是否满足,如果不满足则还需要再次调用 park 方法。
例如根据调用前后中断状态的对比就可以判断是不是因为被中断才返回的。
|
void parkNanos(long nanos)
与 park 方法类似,如果调用 park 方法的线程已经拿到了与 LockSupport 关联的许可证则调用 LockSupport.parkNanos(long nanos) 方法后会马上返回。但是,如果没有拿到许可证,则调用线程会被挂起 nanos 时间后修改为自动返回。
void park(Object blocker)
park方法还支持带有blocker参数的方法,当线程在没有持有许可证的情况下调用park()方法而被阻塞挂起时,这个blocker对象会被记录到该线程内部。使用诊断工具可以观察线程被阻塞的原因,诊断工具是通过调用
getBlocker(Thread thread)方法来获取blocker对象的,所以JDK推荐我们使用带有blocker参数的park方法,并且blocker被设置为 this,这样当在打印线程推展排查问题时就能直到是那个类被阻塞了。使用带
blocker参数的park方法,线程堆栈可以提供更多有关阻塞对象的信息。
public static void park(Object blocker) { |
Thread 类里面有个变量 volatile Object parkBlocker ,用来存放 park 方法传递的 blocker 对象,也就是把 blocker 变量存放到了调用 park 方法的线程的成员变量里面。

void parkNanos(Object blocker, long nanos)
相比 park(Object blocker) 方法多了个超时时间。
void parkUntil(Object blocker, long deadline)
public static void parkUntil(Object blocker, long deadline) { |
其中参数 deadline 的时间单位为 ms,该时间是从 1970 年到现在某一个间点的毫秒值。这个方法和 parkNanos(Object blocker, long nanos)的区别是,后者是从当前算等待 nanos 秒时间,而前者是指定一个时间点,比如需要等到 2017.12.11 日 12:00:00,则把这个时间点转换为从 1970 年到这个时间点的总毫秒数。
示例分析
public class FIFOMutex { |
如上代码是一个先进先出的锁,也就是只有队列的首元素可以获取锁。
抽象同步队列 AQS 概述
AQS–锁的底层支持
AbstractQueuedSynchronized 抽象同步队列简称 AQS,它是实现同步器的基础组件,并发包中所得底层就是使用 AQS 实现的。
另外大多数开发者可能永远不会直接使用
AQS,但是知道其原理对于架构设计还是很有帮助的。
AQS 的类图结构

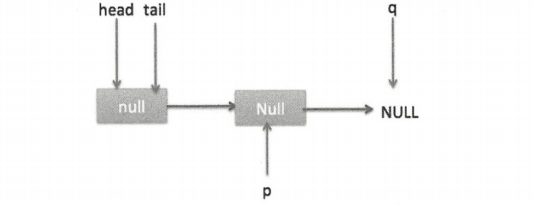
由该图可以看到,AQS 是一个 FIFO 的双向队列,其内部通过节点 head 和 tail 记录队首和队尾元素,队列元素的类型为 Node。
其中 Node 中的 thread 变量用来存放进入 AQS 队列里面的线程;
Node 节点内部的其他参数。
- SHARED 用来标记该线程是获取共享资源时被阻塞挂起后放入
AQS队列的。- EXCLUSIVE 用来标记该线程是否获取独占资源时被挂起后放入
AQS队列waitStatus记录当前线程等待状态,可以为CANCELLED(线程被取消了)、SIGNAL(线程需要被唤醒)、CONDITION(线程在条件队列里面等待)、PROPAGATE(释放共享资源时需要通知其他节点);prev记录当前节点的前驱节点,next记录当前节点的后继节点。
在 AQS 中维持了一个单一的状态信息 state,可以通过 getState、setSate、compareAndSetState 函数修改其值。
对于
ReentrantLock的实现来说,state 可以用来表示当前线程获取锁的可重入次数;对于读写锁
ReentrantReadWriteLock来说,state 的高16位表示读状态,也就是获取该读锁的次数,低16位表示获取到写锁的线程的可重入次数;对于
semaphore来说,state 用来表示当前可用信号的个数;对于
CountDownLatch来说,state 用来表示计数器当前的值。
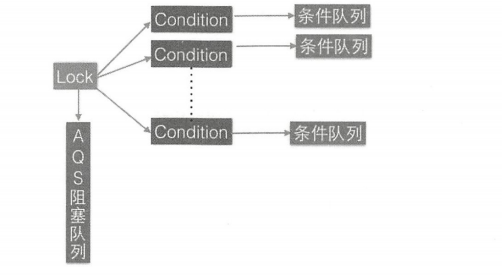
AQS 有个内部类 ConditionObject,用来结合锁实现线程同步。ConditionObject 可以直接访问 AQS 对象内部的变量,比如 state 状态值和 AQS 队列。ConditionObject 是条件变量,每个条件变量对应一个条件队列(单向链表队列),其用来存放调用条件变量的 await 方法后被阻塞的线程,如类图所示,这个条件队列的头、尾元素分别为 firstWaiter 和 lastWaiter。
AQS 的独占方式和共享方式
对于
AQS来说,线程同步的关键是对状态值 state 进行操作。根据 state 是否属于一个线程,操作 state 的方式分为独占方式和共享方式。
在独占方式下获取和释放资源使用的方法为:
void acquire(int arg)、void acquireInterruptibly(int arg)、boolean release(int arg)。在共享方式下获取和释放资源的方法为:
void acquireShared(int arg)、void acquireSharedInterruptibly(int arg)、boolean releaseShared(int arg)
使用独占方式获取到的资源是与具体线程绑定的,就是说如果一个线程获取到了资源,就会标记是这个线程获取到了,其他线程再尝试操作 state 获取资源时会发现当前资源不是自己持有的,就会在失败后被阻塞。
比如独占锁
ReentrantLock的实现,当一个线程获取到了ReentrantLock的锁后,在AQS内部会首先使用CAS操作把 state 状态值从0变为1,然后设置当前锁的持有者为当前线程,当该线程再次获取锁时发现它就是锁的持有者,则会把状态值从1 变为 2,也就是设置可重入次数,而当另一个线程获取锁时发现当前锁已被其他线程持有,就会被放入AQS阻塞队列后挂起。
共享方式的资源与具体线程是不相关的,当多个线程去请求资源时通过 CAS 方式竞争获取资源,当一个线程获取到了资源后,另外一个线程再次去获取时如果当前资源还能满足它的需求,则当前线程只需要使用 CAS 方式进行获取即可。
比如
Semaphore信号量,当一个线程通过acquire()方法获取信号量时,会首先看当前信号量个数是否满足需要,不满足则把当前线程放入AQS阻塞队列,如果满足则通过 自旋CAS获取信号量。
在独占方式下,获取与释放资源的流程如下:
void acquire(int arg)
//当一个线程调用 acquire(int arg) 方法获取独占锁资源时,会首先使用 tryAcquire 方法尝试获取资源 |
boolean release(int arg)
//当一个线程调用 release(int arg) 方法时会尝试使用 tryRelease 操作释放资源, |
注意:**AQS 类并没有提供可用的 tryAcquire 和 tryRelease 方法,也正因 AQS 是锁阻塞和同步器的基础框架一样,tryAcquire 和 tryRelease 需要由具体的子类来实现。实现时要根据具体场景使用 CAS 算法尝试修改 state 状态值,成功返回true,失败返回false。子类还需要定义,在调用 acquire 和 release 方法时 state 状态值的增减代表什么含义。**
比如:继承自
AQS实现的独占锁ReetrantLock,定义当 status 为 0时表示锁空闲,为1时表示锁已经被占用。在重写tryAcquire时,在内部需要使用CAS算法查看当前 state 是否为0,如果为0则使用CAS设置为 1,并设置当前锁的持有者为当前线程,而后返回true,如果CAS失败则返回 false又比如:继承自
AQS实现的独占锁在实现tryRelease时,在内部需要使用CAS算法把当前 state 的值从 1 修改为 0,并设置当前锁的持有者为 null,然后返回 true,如果CAS失败则返回false
共享方式下,获取与释放锁的流程如下:
void acquireShared(int arg)
//当线程调用 acquireShared(int arg)获取共享资源是,会首先使用 tryAcquireShared尝试获取资源, |
boolean releaseShared(int arg)
//当一个线程调用 releaseShared(int arg)时会尝试使用 tryReleaseShared 操作释放资源, |
同理,AQS 类也没有提供可用的 tryAcquireShared 和 tryReleaseShared 方法。具体的方法实现交给子类并定义相关 state 的含义。
基于
AQS实现的锁除了需要重写上面介绍的方法外,还需要重写isHeldExclusively方法,来判断锁是被当前线程独占还是共享。
方法中带有 Interruptibly 关键字的意思事对中断进行响应,也就是线程在调用带有 Interruptibly 关键字的方法获取资源时或者获取资源失败时,其他线程中断了该线程,那么该线程会因为中断而抛出 InterruptedException 异常而返回。也就是说对中断进行响应。反之不带则不做响应。
AQS 入队操作
- 入队操作:当一个线程获取锁失败后该线程会被转化为 Node 节点,然后就会使用
enq(final Node node)
private Node enq(final Node node) { |
如上代码执行入队的过程如下图所示。
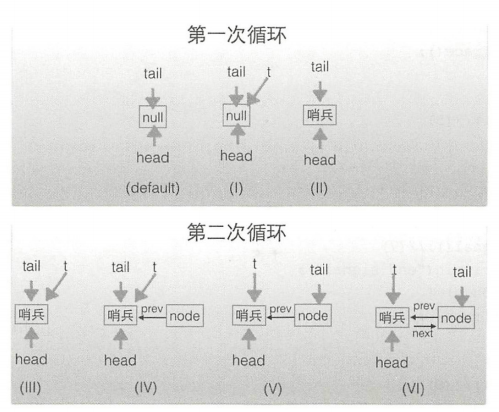
当
AQS队列要插入第一个节点,步骤:首先创建一个哨兵头节点,然后将第一个元素插入哨兵节点的后面
条件变量的支持
首先看一个例子。
|
注意:一个Lock对象可以创建多个条件变量
线程调用条件变量的 await() 方法会阻塞挂起了当前线程。当其他线程调用条件变量的 signal 方法时,被阻塞的线程才会从 await 处返回。
注意:和调用 Object 的
wait方法一样,如果在没有获取到锁前调用了条件变量的await方法则会抛出java.lang.IllegalMonitorStateException异常。
这里的
Lock对象等价于synchronized加上共享变量,调用lock.lock()方法就相当于进入synchronized块(获取了共享变量的内置锁),调用lock.unlock()方法就相当于退出了synchronized块。调用条件变量的await()方法就相当于调用 共享变量的wait()方法,调用条件变量的signal方法就相等于调用共享变量的notify()方法。调用条件变量的signalAll()方法就相当于调用了共享变量的notifyAll()方法。
条件变量
lock.newCondition() 的作用其实是 new 了一个在 AQS 内部声明的 ConditionObject 对象,ConditionObject 是 AQS 的内部类,可以访问 AQS 内部的变量(例如状态变量 state)和方法。在每个条件变量内部都维护了一个条件队列,用来存放调用条件变量的 await() 方法时被阻塞的线程。注意这个队列和 AQS 队列不是一回事。
void await()
当线程调用条件变量的 await() 方法时(必须线调用锁的 lock 方法获取锁),在内部会构造一个类型为 Node.CONDITION 的 node 节点,然后将该节点插入条件队列末尾,之后当前线程会释放获取的锁(也就是会操作锁对应的 state 变量的值),并被阻塞挂起。
public final void await() throws InterruptedException { |
void signal()
当另外一个线程调用条件变量的 signal 方法时(必须先获取锁),在内部会把条件队列里面对头的一个线程节点从条件队列里面移除并放入 AQS 的阻塞队列里面,然后激活这个线程。
public final void signal() { |
注意:
AQS只提供了ConditionObject的实现,并没有提供newCondition函数,该函数用来 new 一个ConditionObject对象。需要由AQS的子类来提供newCondition函数。
下面来看一个线程调用条件变量的 await() 方法而被阻塞后,如何将其放入条件队列。
private Node addConditionWaiter() { |
注意:当多个线程同时调用
lock.lock()方法获取锁时,只有一个线程获取到了锁,其他线程会被转化为 Node 节点插入到 lock 锁对应的AQS阻塞队列里面,并做自旋CAS尝试获取锁。如果获取到锁的线程有调用了对应的条件变量的
await()方法,则该线程会释放获取到的锁,并被转化为 Node 节点插入到条件变量对应的条件队列里面。这时候因为调用
lock.lock()方法被阻塞到AQS队列里面的一个线程会获取到被释放的锁,如果该线程也调用了条件变量的await()方法则该线程也会被放入条件变量的条件队列里面。另外一个线程调用条件变量的
signal()或者signalAll()方法时,会把条件队列里面的一个或者全部 Node 节点移动到AQS的阻塞队列里面,等待时机获取锁。
基于 AQS 实现自定义同步器
基于 AQS 实现一个不可重入的独占锁。
/** |
如上代码中,NonReentrantLock 定义了一个内部类 Sync 用来实现具体的锁的操作,Sync 则继承了 AQS。由于我们实现的是独占模式的锁,所以 Sync 重写了 tryAcquire、tryRelease 和 isHeldExclusively 3个方法。另外,Sync提供了 newCondition 这个方法来支持条件变量。
独占锁 ReentrantLock 的原理
类图结构
ReentrantLock 是可重入的独占锁,同时只能有一个线程可以获取该锁,其他获取该锁的线程会被阻塞而被放入该锁的 AQS 阻塞队列里面。
ReentrantLock类图结构
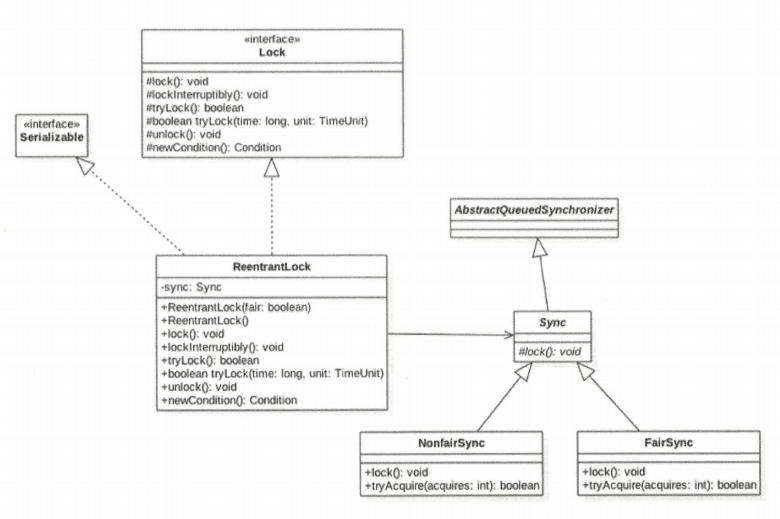
从类图可以看到,ReentrantLock 最终还是通过 AQS 来实现的,并且根据参数来决定其内部是一个公平还是非公平锁,默认非公平锁。
public ReentrantLock() { |
其中 Sync 类直接继承自 AQS ,它的子类 NonfairSync 和 FairSync 分别实现了获取锁的非公平与公平策略。
这里的
AQS状态值表示线程获取该锁的可重入次数,在默认情况下,state 的值为 0 表示当前锁没有被任何线程持有。当一个线程第一次获取该锁时会尝试使用CAS将 state 的值设置为 1,如果CAS成功则当前线程获取了该锁,然后记录该锁的持有者为当前线程。在该线程没有释放锁的情况下第二次获取该锁候,值被设置为 2,这就是可重入次数。在该线程释放该锁时,会使用CAS让状态值减 1,如果减 1 后状态值为 0,则当前线程释放该锁。
获取锁
void lock()
如果锁当前没有被其他线程占用并且当前线程之前没有获取过该锁,则当前线程会获取到该锁,然后设置当前锁的拥有者为当前线程,并设置 AQS 状态值为 1,然后直接返回。如果当前线程之前已经获取过该锁并且没有释放,则这次只是简单的把 AQS 内的状态值加 1 后返回。如果该锁已被其他线程持有,则调用该方法的线程会被放入 AQS 队列后阻塞挂起。
public void lock() { |
如上代码中,ReentrantLock 的 lock() 委托给了 sync,而根据前面提到的在构造函数中会选择 sync 的实现是 NonfairSync 还是 FairSync,这个锁是一个非公平锁或者公平锁。
这里先看 sync 的子类 NonfairSync 的情况。
final void lock() { |
因为默认 AQS 的状态值为0,所以第一个调用的 Lock 的线程会通过 CAS 设置状态值为 1,CAS 成功则表示当前线程获取到了锁,然后 setExclusiceOwnerThread 设置该锁持有者是当前线程。
如果此时有其他线程调用 lock 方法企图获取该锁,CAS 会失败,然后回调用 AQS 的 acquire 方法。注意:传递参数为 1
前面说过 AQS 并没有提供可用的 tryAcquire 等方法,ReetrantLock 的 sync 的子类继承了 AQS 并实现了那些方法。
先看 NonfairSync 中的实现。
protected final boolean tryAcquire(int acquires) { |
不公平体现在,当一个线程释放锁前,
AQS阻塞队列中有若干线程正在阻塞。这时线程释放了锁,有另外一个线程执行到了这里准备获取锁,它并不会查看当前AQS队列里面是否有比自己更早请求该锁的线程。他会与阻塞队列里面的第一个线程竞争该锁(谁调用CAS修改了AQS状态值归谁)。
接下来我们来看看 FairSync 的 tryAcquire 方法实现。来看看公平是怎么体现的。
protected final boolean tryAcquire(int acquires) { |
可以看到公平的 tryAcquire 策略与非公平的唯一区别就是,在发现 state 为0 时去获取的锁会先调用 hasQueuePredcessors 方法判断 AQS 队列中是否有更早请求的线程。
hasQueuePredcessors 该方法也是实现公平性的核心代码
public final boolean hasQueuedPredecessors() { |
上述返回的代码处,如果
h==t则说明当前队列为空,直接返回 false;如果h != t并且s == null则说明有一个元素将要作为第一个节点入队(enq函数的第一个元素入队列是两步操作:首先创建一个哨兵头节点,然后将第一个元素插入哨兵节点的后面),那么返回 true;如果h != t并且s != null和s.thread != Thread.currendtThread()则说明队列里面的第一个元素不是当前线程,那么返回 true。
void lockInterruptibly()
该方法与 lock() 类似,区别在于它对中断进行响应。
public void lockInterruptibly() throws InterruptedException { |
boolean tryLock()
尝试获取锁,如果当前该锁没有被其他线程持有,则当前线程获取该锁并返回 true,否则返回 false。注意:该方法不会引起当前线程阻塞。
public boolean tryLock() { |
如上代码与 非公平锁的 tryAcquire() 方法底层代码相同,所以 tryLock() 使用的是非公平策略。
boolean tryLock(long timeout, TimeUnit unit)
尝试获取锁,与 tryLock() 不同之处在于,它设置了超时时间,如果超时时间到了没有获取到锁则返回 false。
public boolean tryLock(long timeout, TimeUnit unit) |
释放锁
void unlock()
尝试释放锁,如果当前持有该锁,则调用该方法会让该线程对该线程持有的 AQS 状态值减 1,如果减去 1 后当前状态值为 0 ,则当前线程会释放该锁,否则仅仅减 1 而已。如果当前线程没有持有该锁而调用了该方法则会抛出 IllegalMonitorStateException 异常。
public void unlock() { |
读写锁 ReetrantReadWriteLock 的原理
解决线程安全问题使用 ReentrantLock 就可以,但是 ReentrantLock 是独占锁,某时只有一个线程可以获取该锁,而实际中会有写少读多的场景,显然 ReentrantLock 满足不了这个需求,所以 ReentrantReadWriteLock 应运而生。ReentrantReadWriteLock 采用读写分离的策略,允许多个线程可以同时获取读锁。
类图结构
为了了解 ReentrantReadWriteLock 的内部结构,我们先看它的类图结构
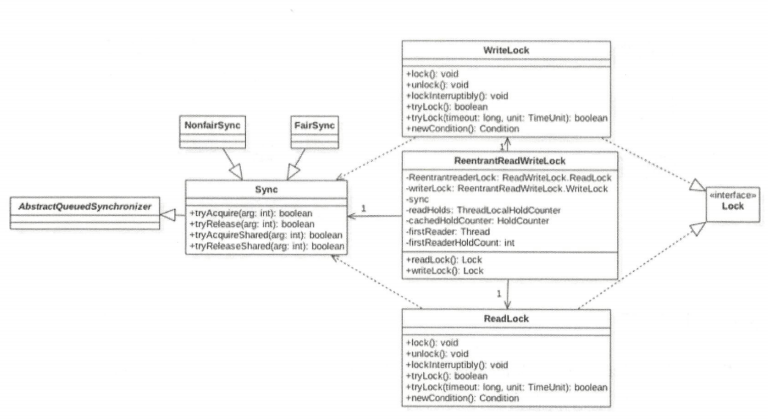
读写锁的内部维护了一个 ReadLock 和 一个 WriteLock,它们依赖 Sync 实现具体功能。而 Sync 继承自 AQS,并且也提供了公平和非公平的实现。
ReetrantReadWriteLock很巧妙的使用了AQS的 state 状态,使用 state 的高16位标识读状态,低16位表示写状态。
static final int SHARED_SHIFT = 16; |
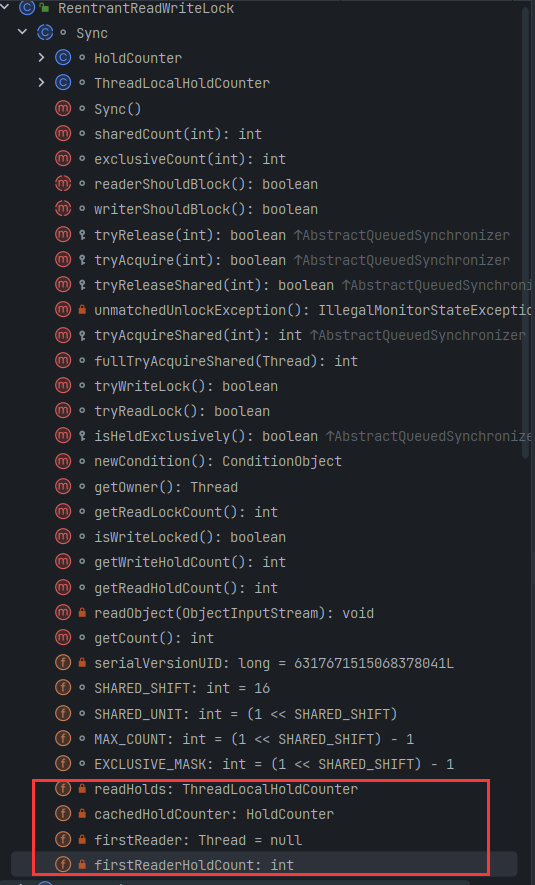
其中 firstReader 用来记录第一个获取到读锁的线程,firstReaderHoldCount 则记录第一个获取到读锁的线程获取读锁的可重入次数。cachedHoldCounter 用来记录最后一个获取读锁的线程获取读锁的可重入次数。
static final class HoldCounter { |
readHolds 是 ThreadLocal 变量,用来存放除去第一个获取读锁线程外的其他线程获取读锁的可重入次数。ThreadLocalHoldCounter 继承了 ThreadLocal,因而 initalValue 方法返回一个 HoldCounter 对象。
static final class ThreadLocalHoldCounter |
写锁的读取与释放
在 ReentrantReadWriteLock 中写锁使用 WriteLock 来实现。
void lock()
写锁是个独占锁,某时只有一个线程可以获取该锁。如果当前没有线程获取到读锁和写锁,则当前线程可以获取到写锁然后返回。如果当前已经有线程获取到读锁或写锁,则当前请求写锁的线程会被阻塞挂起。另外写锁是可重入锁,如果当前线程已经获取了该锁,再次获取只是简单地把可重入次数加 1 后直接返回。
public void lock() { |
如上代码,在 lock() 内部调用了 AQS 的 acquire 方法,其中 tryAcquire 是 ReentrantReadWriteLock 内部的 sync 类重写的,代码如下:
protected final boolean tryAcquire(int acquires) { |
对于 witerShouldBlock() 方法,非公平锁的实现为
final boolean writerShouldBlock() { |
对于非公平锁来说调用该方法总是返回 false ,则 代码(1) 抢占式执行 CAS 获取读写锁,获取成功返回 true,否则 false。
公平锁实现为
final boolean writerShouldBlock() { |
这里还是使用 hashQueuePredecessors 来判断当前线程节点是否有前驱节点,如果有则当前线程放弃获取写锁的权限,直接返回 false。
void lockInterruptibly()
类似于 lock() ,不同在于它会对中断进行响应。
public void lockInterruptibly() throws InterruptedException { |
boolean tryLock()
尝试获取写锁,如果当前线程没有其他线程持有写锁或者读锁,则当前线程获取写锁会成功,然后返回 true。如果当前已经有其他线程持有写锁或者读锁则该方法直接返回false,且当前线程并不会被阻塞。如果当前线程已经持有该写锁则该方法直接返回false,且当前线并不会被阻塞。如果当前线程已经有了该写锁则简单增加 AQS 的状态值后返回 true。
public boolean tryLock( ) { |
如上代码与 tryAcquire 方法类似。
boolean tryLock(long timeout, TimeUnit unit)
与 tryAcquire() 不同之处在于,多了超时时间参数,如果尝试获取写锁失败则会把当前线程挂起指定时间,待超时时间到后当前线程被激活,如果还是没有获取到写锁则会返回 false。另外该方法会对中断响应。
public boolean tryLock(long timeout, TimeUnit unit) |
void unlock()
尝试释放锁,如果当前线程持有该锁,调用该方法会让该线程对持有的 AQS 状态值减 1,如果减去 1 后当前状态值为 0 则当前线程会释放该锁,否则仅仅减一而已,如果当前线程没有持有该锁而调用该方法则会抛出 IllegalMonitorStateException 异常。
public void unlock() { |
读锁的获取与释放
void lock()
获取读锁,如果当前没有其他线程持有写锁,则当前线程可以获取读锁,AQS 的状态值 state 的高 16 位的值会增加 1,然后方法返回。否则如果其他一个线程持有写锁,则当前线程会被阻塞。
public void lock() { |
如果当前获取读锁的线程已经持有了写锁,则也可以获取读锁。但是注意,当一个线程先获取了写锁,然后获取了读锁处理事情完毕后,要记得把读锁和写锁都释放掉,不能只释放写锁。
readerShouldBlock 再非公平锁中的实现
final boolean readerShouldBlock() { |
如上代码的作用是,如果队列里面存在一个元素,则判断第一个元素是不是正在尝试获取写锁,如果不是,则当前线程判断当前获取读锁的线程是否达到了最大值。最后执行 CAS 操作 AQS 状态值的高 16 位增加 1。
如果 readerShouldBlock 返回 true 则说明有线程正在获取写锁,所以执行 fullTryAcquireShared(current)。fullTryAcquireShared(current) 代码与 tryAcquireShared 类似,它们的不同之处在于,前者通过循环自旋获取。
final int fullTryAcquireShared(Thread current) { |
void lockInterruptibly()
类似与 lock() 方法,不同之处在于,该方法会对中断进行响应。
public void lockInterruptibly() throws InterruptedException { |
boolean tryLock()
尝试获取锁,如果当前没有其他线程持有写锁,则当前线程获取读锁成功,然后返回 true。如果当前已经有其他线程持有写锁则该方法直接返回 false,但当前线程并不会被阻塞。如果当前线程已经持有了该读锁则简单增加 AQS 的状态值的高 16 位后直接返回 true。
public boolean tryLock() { |
boolean tryLock(long timeout, TimeUnit unit)
与 tryLock() 的不同之处在于,多了超时时间参数,如果尝试获取读锁失败则会把当前线程挂起指定时间,待超时时间到了后当前线程被激活,如果此时还没有获取到锁则返回 false。另外,该方法对中断响应。
public boolean tryLock(long timeout, TimeUnit unit) |
void unlock()
public void unlock() { |
如上代码,在无限循环里面,如果更新 state 成功则查看当前 AQS 状态值是否为 0,为 0 则说明当前已经没有读线程占用读锁,则返回 true。然后回调用 doReleaseShared 方法释放一个由于获取写锁而被阻塞的线程,如果当前 AQS 状态值不为 0,则说明当前还有线程持有了读锁,所以返回 false。如果 tryReleaseShared 中的 CAS 更新 AQS 状态值失败,则自旋重试直到成功。
总结
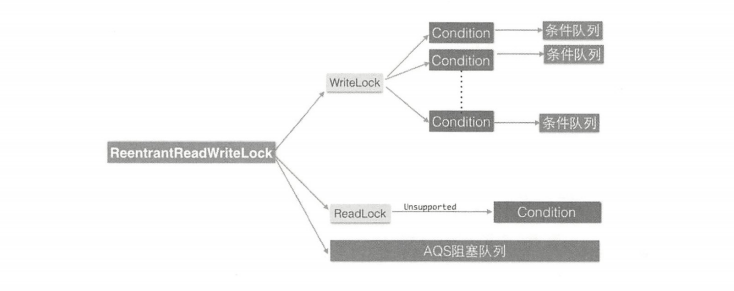
最后使用一张图片来加深对 ReentrantReadWriteLock 的理解。
JDK 8 中新增的 StampedLock 锁探究
概述
StampedLock 是并发包里面 JDK 8 版本新增的一个锁,该锁提供了三种模式的独写控制,当调用获取锁的系列函数是,会返回一个 long 型的变量,我们称之为戳记(stamp),这个戳记代表了锁的状态。其中 try 系列获取锁的函数,当获取锁失败后会返回为 0 的 stamp 值。当调用释放锁和转换锁的方法时需要传入获取锁时返回的 stamp 值。
StampedLock 提供的三种独写模式锁分别如下。
**写锁
writeLock**:是一个排它锁和独占锁,某时只有一个线程可以获取该锁,当一个线程获取该锁后,其他请求读锁和写锁的线程必须等待,这类似于ReentrantReadWriteLock的写锁(不同的时这里的写锁是不可重入锁);当目前没有线程持有读锁或者写锁时才可以获取到该锁。请求该锁成功后会返回一个 stamp 变量用来表示该锁的版本,当释放该锁时需要调用unlockWrite方法并传递获取锁时的 stamp 参数。并且它提供了非阻塞的tryWriteLock方法。**悲观读锁
readLock**:是一个共享锁,在没有线程获取独占写锁的情况下,多个线程可以同时获取该锁。如果已经有线程持有写锁,则其他线程请求获取该读锁会被阻塞,这类似于ReentrantReadWriteLock的读锁(不同的是这里的读锁是不可重入锁)。这里说的悲观试着在具体操作数据前其会悲观地认为其他线程可能要对自己操作的数据进行修改,所以需要先对数据加锁,这时在读少写锁的情况下的一种考虑。请求该锁成功后会返回一个 stamp 变量用来表示该锁的版本,当释放该锁时需要调用unlockRead方法并传递 stamp 参数。并且它提供了非阻塞的tryReadLock方法。**乐观读锁
tryOptimisticRead**:它是相对于悲观锁来说的,在操作数据前并没有通过CAS设置锁的状态,仅仅通过位运算测试。如果当前没有线程持有写锁,则简单地返回一个非 0 的 stamp版本信息。获取该 stamp 后在具体操作数据前还需要调用 validate 方法验证该 stamp 是否已经不可用,也就是看当前调用tryOptimisticRead返回 stamp 后到当前时间期间是否有其他线程持有该锁,如果是则 validate 会返回 0,否则就看也使用该 stamp 版本的锁对数据进行操作。由于tryOptimisticRead并没有使用CAS设置锁的状态,所以不需要显示地释放该锁。该锁的一个特点是适用于 读多写少的场景,因为获取读锁只是使用位操作进行检验。不涉及CAS操作,所以效率会高很多,但是同时由于没有使用真正的锁,在保证数据一致性上需要赋值一份到要操作的变量到方法栈,并且在操作数据时可能其他线程已经修改了数据,而我们操作的是方法栈里面的数据,也就是一个快照,所以最多返回的不是最新的数据,但是一致性还是得到保障的。
StampedLock还支持这三种锁在一定条件下进行相互转换。例如long tryConvertToWriteLock(long stamp)期望把 stamp 表示的锁升级为写锁,这个函数会在下面几种情况下返回一个有效的 stamp(也就是晋升写锁成功):
- 当前锁已经是写锁模式了。
- 当前锁处于读锁模式,并且没有其他线程是读锁模式
- 当前处于乐观锁模式,并且当前写锁可用。
另外,
StampLock的读写锁都是不可重入锁,所以在获取锁后释放锁前不应该再调用会获取锁的操作,以避免调用线程被阻塞。当多个线程同时尝试获取读锁和写锁时,谁先获取锁没有一定的规则,完全都是尽力而为,是随机的。并且该锁不是直接实现Lock或ReadWriteLock接口,而是在其内部自己维护了一个双向阻塞队列。
案例
Point 类里面有两个成员变量(x, y)用来表示一个点的二维坐标,和三个操作坐标变量的方法。另外实例化了一个 StampedLock 对象用来保证操作的原子性。
class Point { |
使用乐观读锁还是很容易犯错误的,必须要小心,且必须要保证如下的使用顺序。
long stamp = lock.tryOptimisticRead(); //非阻塞获取版本信息 |
总结
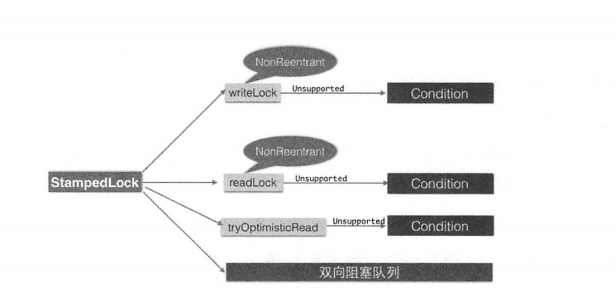
最后通过一张图来一览 StampedLock 的组成。
第七章 Java 并发包中并发队列原理剖析
JDK 中提供了一系列场景的并发安全队列。总的来说,按照实现方式的不同可分为阻塞队列和非阻塞队列,前者使用锁实现,而后者则使用 CAS 非阻塞算法实现。
ConcurrentLinkedQueue 原理探究
ConcurrentLinkedQueue 是线程安全的无界非阻塞队列,其底层数据结构使用单向链表实现,对于入队和出队操作使用 CAS 来实现线程安全。
类图结构
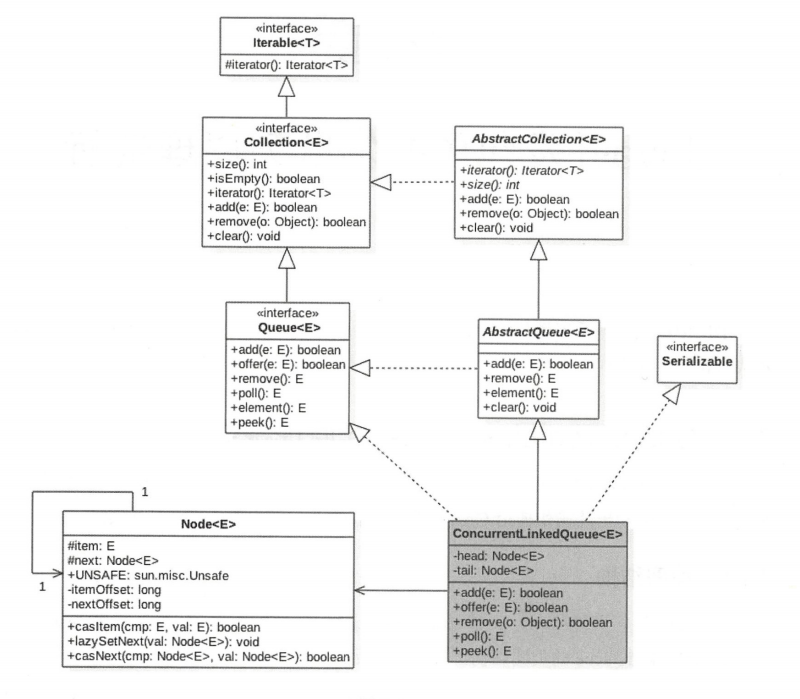
ConcurrentLinkedQueue 内部的队列使用单向链表的方式实现,其中有两个 volatile 类型的 Node 节点分别用来存放队列的首、尾结点。从下面的无参构造函数可知,默认头、尾结点都是指向 item 为 null 的哨兵节点。新元素会被插入队列末尾,出队时从队列头部获取一个元素。
public ConcurrentLinkedQueue() { |
在 Node 节点内部则维护一个使用 volatile 修饰的变量 item,用来存放节点的值;next 用来存放链表的下一个节点,从而链接为一个单向无界链表。其内部则使用 UnSafe 工具类提供的 CAS 算法来保证出入队时操作链表的原子性。
原理介绍
本节介绍 ConcurrentLonkedQueue 的几个方法的实现原理
offer操作
offer 操作是在队列末尾添加一个元素,如果传递的参数是 null 则抛出 NPE 异常,否则由于 ConcurrentLinkedQueue 是无界队列,该方法一定会返回 true。另外由于使用 CAS 无阻塞算法,因此该方法不会阻塞挂起调用线程。
public boolean offer(E e) { |
下面结合图来讲解该方法的执行流程。
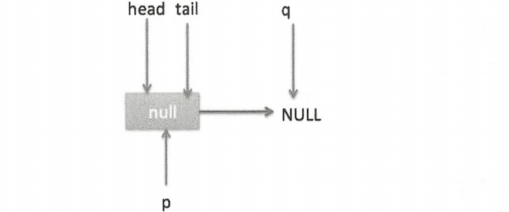
在对空参进行空检查后(如果为空则抛出 NPE 异常),使用 item 作为构造函数参数创建一个新的节点,然后从队列尾部节点开始循环,打算从尾部添加元素。
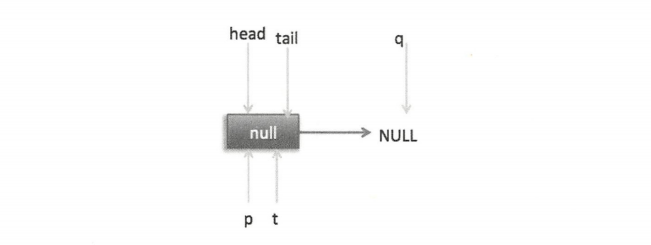
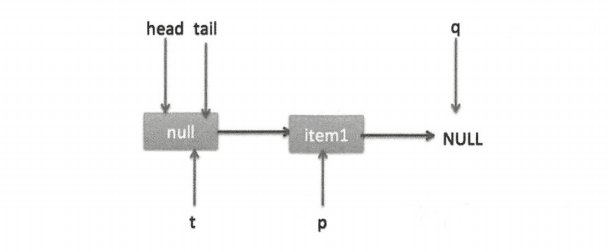
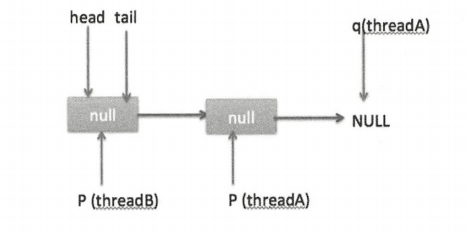
这时节点 p、t、head、tail 同时指向了 item 为 null 的哨兵节点,由于哨兵节点的 next 节点为 null,所以这里 q 也指向 null。代码发现 q==null 则通过 CAS 原子操作判断 p 的节点是否为 null,如果为 null 则使用节点 newNode 替换 p 的 next 节点。这里由于 p == t 所以没有设置尾部节点,然后退出 offer 方法。这时队列状态如下图。
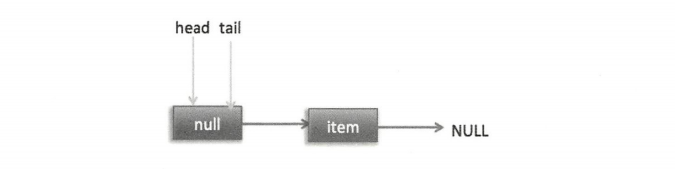
上面是一个线程调用 offer 方法的情况,如果多个线程同时调用,就会存在多个线程同时执行到设置 p 的 next 节点替换为 newNode 的情况。假设线程 A 调用 offer(item1),线程 B 调用 offer(item2),同时执行到 p.casNext(null,newNode) 。由于 CAS 的比较设置操作是原子性的,所以这里假设线程 A 先执行了比较设置操作,发现当前 p 的 next 节点确实是 null,则会原子性地更新 next 节点为 item1,这时候线程 B 也会判断 p 的next 节点是否为 null,结果发现不为 null(因为线程 A 已经设置了 p 的 next 节点为 item1),则会进入下一次循环判断 q 是否为null。这时队列分布如下图。
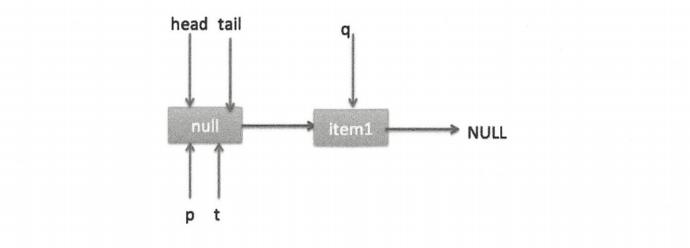
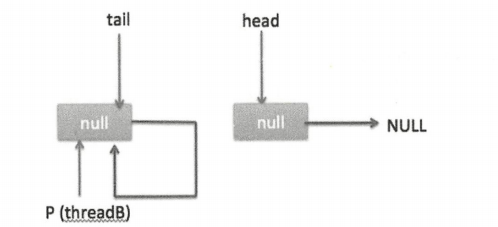
根据上面的状态图可知 q 并不为空,则会执行最后一条 else 代码,寻找尾节点,然后把 q 赋给了 p,这时队列状态如下图。
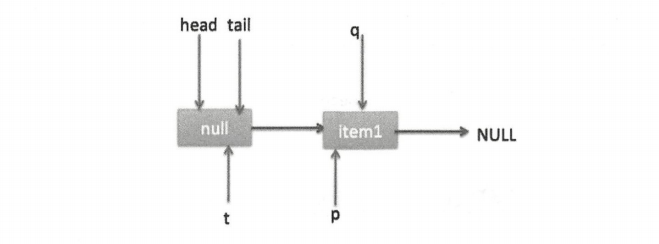
再次循环,此时的 p 指向 item1 所以 q(p 的 next 节点) 为 null,又去执行 p.casNext(null,newNode) 成功则将 item2 替换 p 的 next 节点。注意此时 p != t,需要更新 t 的指向,调用 casTail(t, newNode) 让 t 指向新的尾节点,最后返回 true 然后退出。状态如下两图。
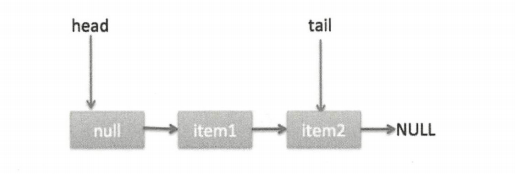
分析到现在,就差 (7),其实这一步要在执行 poll 操作后才会执行。这里先看一下执行 poll 操作后可能会存在的一种情况,如下图。
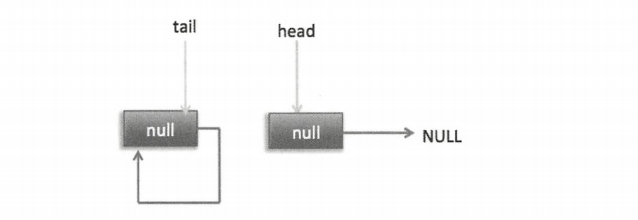
下面分析当队列处于这种状态时调用 offer 添加元素,执行到代码 (4) 时的状态图如下图。
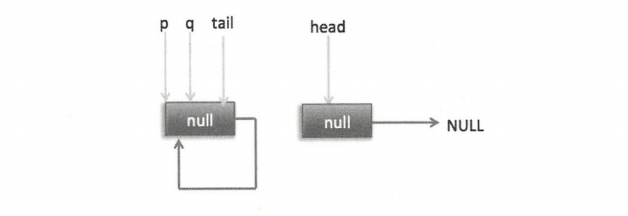
这里由于 q 节点不为空并且 p == q所以执行代码 (7),由于 t==tail 所以 p 被赋值为 head,然后重新循环,循环后执行到代码 (4),这时候队列状态如下图所示。
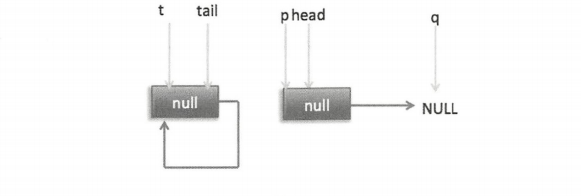
这时由于 q==null,所以执行代码 (5) 进行 CAS 操作,如果当前没有其他线程执行 offer 操作,则 CAS 操作会成功,p 的next 节点被设置为 新增节点。然后执行代码 (6) ,由于 p != t 所以设置新节点为队列的尾部节点,现在队列状态如下图。

可见,offer 操作的关键步骤是代码 (5),通过原子
CAS操作来控制某事只有一个线程可以追加元素到队列末尾。进行CAS竞争失败的线程会通过循环一次次尝试进行CAS操作,直到成功才返回,也就是通过使用CAS自旋锁不断尝试方式来代替阻塞算法挂起调用线程。相比阻塞算法,这是使用 CPU 资源换取阻塞所带来的开销。
add操作
add 操作是在链表的末尾添加一个元素,其实在内部调用的还是 offer 操作。
public boolean add(E e) { |
poll操作
poll 操作是在队列头部获取并移除一个元素,如果队列为空则返回 null。
public E poll() { |
结合图来讲解代码的执行逻辑
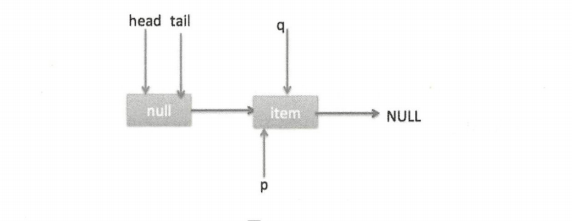
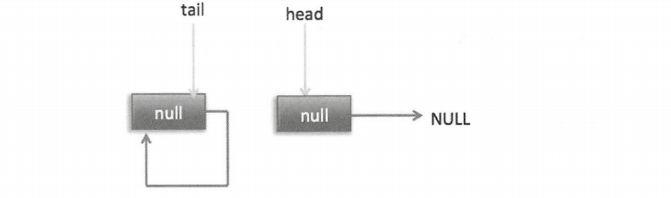
I. poll 操作是从队列的头获取元素,所以执行(2)内层循环是从 head 节点开始迭代,代码(3)获取当前队列头的节点,队列一开始为空时状态如下图。
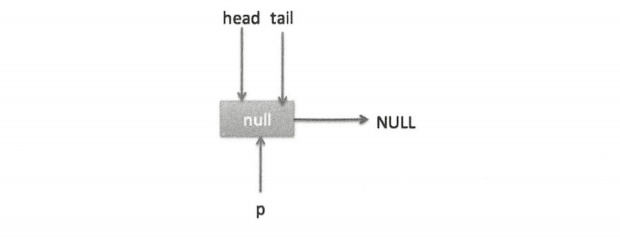
由于 head 节点指向的是 item 为 null 的哨兵节点,所以会执行到代码(6),假设这个过程中没有线程调用 offer 方法,则此时 q 等于 null,这时候队列状态如下图。
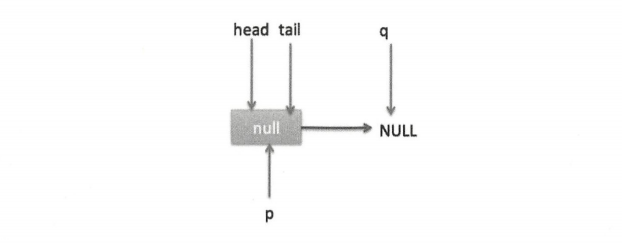
所以会执行 updateHead 方法,由于 h 等于 p 所以没有设置头节点,poll 方法直接返回 null。
II. 假设执行到代码 (6) 时已经有其他线程调用了 offer 方法并成功添加一个元素到队列,这时候 q 指向的是新增元素的节点,此时队列状态如图。
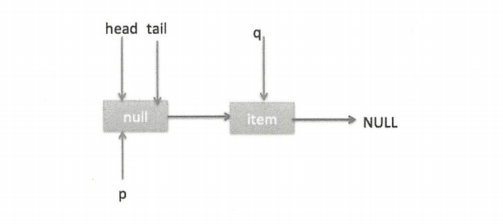
所以代码(6)的判断结果为 false,然后会转向执行代码(7),而此时 p 不等于 q,所以转向执行代码 (8),执行的结果是 p 指向了 q,此时队列状态如下图。
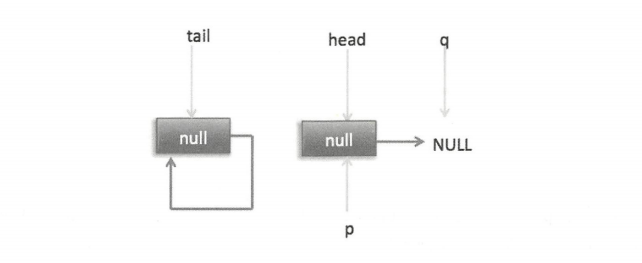
然后程序转向执行代码 (3),p 现在指向的元素值不为 null,则执行 p.casItem(item,null) 通过 CAS 操作尝试设置 p 的 item 值为 null,如果此时没有其他线程进行 poll 操作,则 CAS 成功会执行代码(5),由于此时 p != h 所以设置头节点为 p,并设置 h 的 next 节点为 h 自己,poll 然后返回被从队列移除的节点值 item。此时队列状态如下图。
III. 假如现在一个线程调用了 poll 操作,则正在执行代码(4)时队列状态如下图所示。
这时执行代码(6)返回 null。
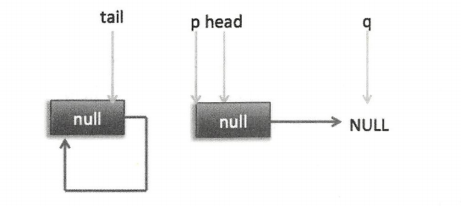
IV. 现在 poll 的代码还有分支(7)没有执行过,那么什么时候会执行呢?下面来看看。假设线程 A 执行 poll 操作时当前队列状态如下图所示。
那么执行 p.casItem(item,null) 通过 CAS 尝试设置 p 的 item 值为 null,假设 CAS 设置成功则标记该节点并从队列中将其移除,此时队列状态如下图。
然后,由于 p != h,所以会执行 updateHead 方法,假如线程 A 执行 updateHead 前另外一个线程 B 开始 poll 操作,这时候线程 B 的 p 指向 head 节点(线程 A 还没来得及更新头结点),但是还没有执行到代码(6),这时候队列状态如下图所示。
然后此时线程 A 执行 updateHead 操作,执行完毕后线程 A 退出,这时候队列状态如图所示。
然后线程 B 继续执行代码(6),q = p.next,由于该节点是子引用节点,所以 p == q,所以会执行代码(7)跳到外出循环 restartFromHead,获取当前队列头 head,现在的状态如下图。
总结:poll 方法在移除一个元素时,只是简单的使用 CAS 操作把当前节点的 item 值设置为 null,然后通过重新设置头节点将该元素从队列里面移除,被移除的节点就成了孤立节点,这个节点会在垃圾回收时被回收掉。另外如果在执行分支中发现头节点被修改了,要跳到外层循环重新获取新的头节点。
peek操作
public E peek() { |
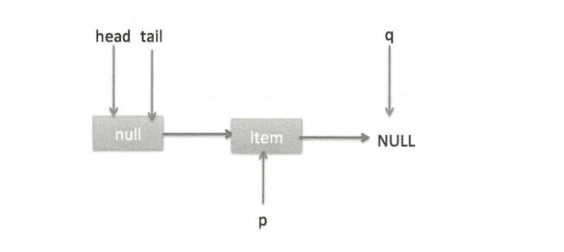
peek 操作的代码结构与 poll 类似,不同之处在于代码(3)中少了 castItem。其实这很正常,因为 peek 只是获取队列头元素值,并不清空其值。根据前面的介绍我们知道第一次执行 offer 后 head 指向的是哨兵节点(也就是 item 为 null 的节点),那么第一次执行 peek 时在代码(3)中会发现 item == null,然后执行 q=p.next,这时候 q 节点指向的才是队列里面第一个真正的元素,或者如果队列为 null 则 q 指向 null。
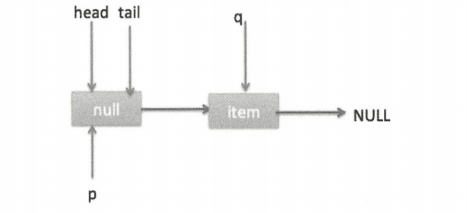
当队列为空时队列状态如图。
这时候执行 updateHead,由于 h 节点等于 p 节点,所以不进行任何操作,然后 peek 操作会返回 null。
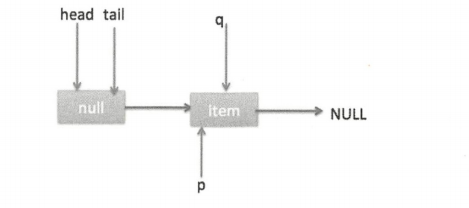
当队列中至少有一个元素时(这里假设只有一个),队列状态如下图。
这时候执行代码(5),p 指向了 q 节点,然后执行代码(3),此时队列状态如下图。
执行代码(3)时发现 item 不为 null,所以执行 updateHead 方法,由于 h != p,所以设置头节点,设置后队列状态如下图所示。
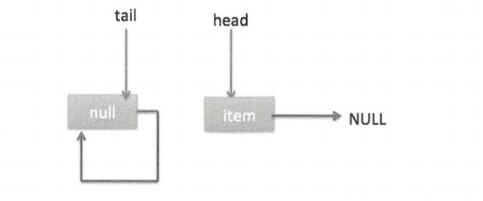
也就是提出了哨兵节点。
总结:peek 操作的代码与 poll 操作类似,只是前者只获取队列头元素但是并不从队列里面将它删除,而后者获取后需要从队列里面将他删除。另外,在第一次调用 peek 操作时,会删除哨兵节点,并让队列的 head 节点指向队列里面第一个元素或者 null。
size操作
计算当前队列元素个数,在并发环境下不是很有用,因为 CAS 没有加锁,所以从调用 size 函数到返回结果期间有可能增删元素,导致统计元素个数不精确。
public int size() { |
remove操作
如果队列里面存在该元素则删除该元素,如果存在多个则删除第一个,并返回true,否则返回false。
public boolean remove(Object o) { |
contains操作
判断队列里面是否含有指定队列,由于是遍历整个队列,所以像 size 操作一样结果也不是那么精准,有可能调用该方法时元素还在队列里面,但是遍历过程中其他线程才把该元素删除,那么就会返回 false。
public boolean contains(Object o) { |
小结
如图所示,入队、出队都是操作使用 volatile 修饰的 tail、head 节点,要保证在多线程下出入队线程安全,只需要保证这两个 Node 操作的可见性和原子性即可。由于 volatile 本身可以保证可见性,所以只需要保证对两个变量原子操作的原子性即可。
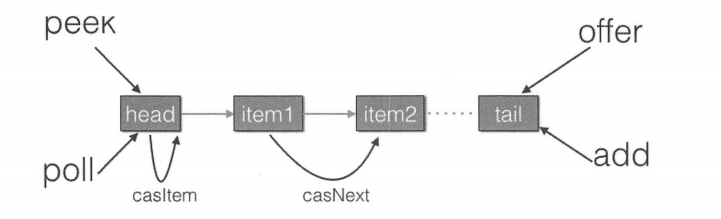
offer 操作是在 tail 后面添加元素,也就是调用 tail.casNext 方法,而这个方法使用的是 CAS 操作,只有一个线程会成功,然后失败的线程会循环,重新获取 tail,再执行 casNext 方法。 poll 操作也通过类似 CAS 的算法保证出队是移除节点操作的原子性。
LinkedBlockingQueue 原理探究
前面介绍了使用 CAS 算法实现的非阻塞队列 ConcurrentLinkedQueue,下面我们来介绍使用独占锁实现的阻塞队列 LinkedBlockingQueue。
类图结构
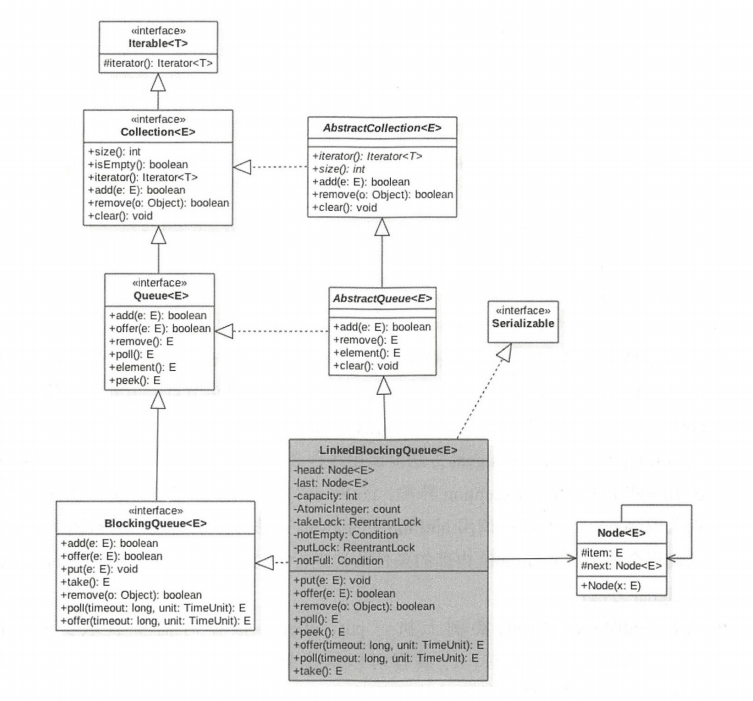
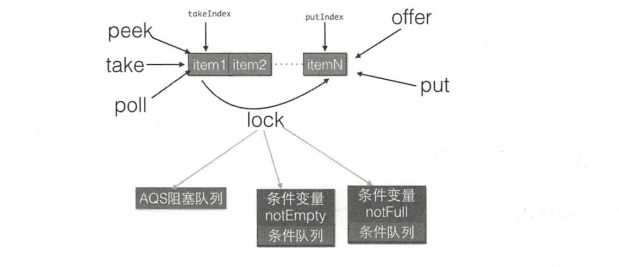
由类图可以看到,LinkedBlockingQueue 也是使用单向链表实现的,其也有两个 Node,分别用来存放 首、尾节点,并且还有一个初始值为 0 的原子变量 count,用来记录队列元素个数。另外还有两个 ReentrantLock 的实例,分别用来控制元素入队和出队的原子性,其中 tackLock 用来控制同时只有一个线程可以从队列头获取元素,其他线程必须等待,putLock 控制通知只能有一个线程可以获取锁,在队列尾部添加元素,其他线程必须等待。另外,notEmpty 和 notFull 是条件变量,他们内部都有一个条件队列用来存放入队和出队时被阻塞的线程,其实这时生产者–消费者模型。如下是独占锁的创建代码。
//执行 take、poll等操作时需要获取该锁 |
- 当调用线程在
LinkedBlockingQueue实例上进行出队等操作时需要获取tackLock锁,从而保证同时只有一个线程可以操作链表头节点。另外由于条件变量notEmpty内部的条件队列的维护使用的时tackLock的锁状态管理机制,所以在调用notEmpty的 await 和 signal 方法前调用线程必须先获取到tackLock锁,否则会抛出IllegalMonitorStateException异常。notEmpty内部则维护着一个条件队列,当线程获取到takeLock锁后调用notEmpty的 await 方法时,调用线程会被阻塞,然后该线程会被方法notEmpty内部的条件队列进行等待,知道有线程调用了notEmpty的signal 方法。- 在
LinkedBlockingQueue实例上执行入队操作时需要获取putLock锁,从而保证同时只有一个线程可以操作链表尾节点。同样由于条件变量notFull内部的条件队列的维护使用的时putLock的锁状态管理机制,所以在调用notFull的 await 和 signal 方法前调用线程必须先获取到putLock锁,否则会抛出IllegalMonitorStateException异常。notEmpty内部则维护着一个条件队列,当线程获取到putLock锁后调用notFull的 await 方法时,调用线程会被阻塞,然后该线程会被方法notFull内部的条件队列进行等待,知道有线程调用了notFull的signal 方法。
LinkedBlockingQueue 的无参构造函数
public static final int MAX_VALUE = 0x7fffffff; |
由该代码可知,默认队列容量为 0x7ffffff,用户也可自己指定容量,所以从一定程度上可以说 LinkedBlockingQueue 是有界阻塞队列。
原理介绍
offer操作
向队列尾部插入一个元素,如果队列中有空闲则插入成功后返回 true,如果队列已满则丢弃当元素然后返回 false。如果 e 元素为 null 则抛出 NullPointerException 异常。另外该方法是不阻塞的。
public boolean offer(E e) { |
代码(7)处执行了 signalNotEmpty操作,我们来看看它的代码实现。
private void signalNotEmpty() { |
该方法的作用就是激活 notEmpty 的条件队列中因为调用 notEmpty 的 await 方法(比如调用 take 方法并且队列为空的时候)而被阻塞的一个线程,这也说明调用条件变量的方法前要先获取对应的锁。
注意:入队时只操作队列链表的尾节点。
put操作
向队列尾部插入一个元素,如果队列中有空闲则插入后直接返回,如果队列已满则阻塞当前线程,直到队列有空闲插入成功后返回。如果在阻塞时被其他线程设置了中断标志,则被阻塞线程会抛出 InterruptedException 异常而返回。另外,如果 e 元素为 null 则抛出 NullPointerException 异常。
put 操作的代码结构与 offer 操作类似,代码如下。
public void put(E e) throws InterruptedException { |
poll操作
从队列头部获取并移除一个元素,如果队列为空则返回 nulll,该方法是不阻塞的。
public E poll() { |
代码(6)说明移除队列元素前当前队列是满的,移除对头元素后当前元素至少有一个空闲位置,那么这是用可以调用 signalNotFull 激活因为调用 put 方法而被阻塞到 notFull 的条件队列里的一个线程。
private void signalNotFull() { |
获取元素时只操作了队列的头节点
peek操作
获取队列头部元素但是不从队列里面移除它,如果队列为空则返回 null。该方法是不阻塞的。
public E peek() { |
take操作
获取当前队列头部元素并从队列里面移除它。如果队列为空则阻塞当前线程直到队列不为空然后返回元素,如果在阻塞时被其他线程设置了中断标志,则被阻塞线程会抛出 InterruptedException 异常而返回。
public E take() throws InterruptedException { |
remove操作
删除队列里面指定的元素,有则删除并返回 true,没有则返回 false。
public boolean remove(Object o) { |
代码(1)通过 fullyLock 获取双重锁,获取后,其他线程进行入队或者出队操作时就会被阻塞挂起。
void fullyLock(){ |
代码(2)遍历队列寻找要删除的元素,找不到则直接返回 false,找到则执行 unlink 操作。
void unlink(Node<E> p, Node<E> trail) { |
删除元素后,如果发现当前队列有空闲空间,则唤醒 notFull 的条件队列中的一个因为调用 put 方法而被阻塞的线程。
代码(5)调用 fullyUnlock 方法使用与加锁顺序相反的顺序释放双重锁。
void fullyUnlock(){ |
总结:由于 remove 方法在删除指定元素前加了两把锁,所以在遍历队列查找指定元素的过程中是线程安全的,并且此时其他调用入队、出队操作的线程全部会被阻塞。另外获取多个资源锁的顺序与释放的顺序是相反的。
size操作
获取当前队列元素个数。
public int size() { |
由于进行出队、入队操作时的 count 是加了锁的,所以结果相比 ConcurrentLinkedQueue 的 size 方法比较准确。ConcurrentLinkedQueue 的出队、入队操作不是原子性的,所以会不准确。
小结
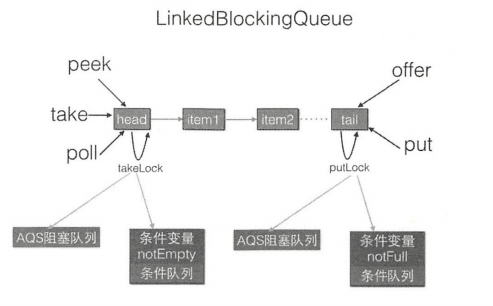
如图所示,对头、尾节点的操作分别使用了单独的独占锁从而保证了原子性,所以出队和入队操作是可以同时进行的。另外对头、尾节点的独占锁都配备了一个条件队列,用来存放被阻塞的线程,并结合入队、出队操作实现了一个生产消费模型。
ArrayBlockingQueue 原理探究
上面介绍了使用有界链表方式实现的阻塞队列 LinkedBlockQueue,本节来研究使用有界数组方式实现的阻塞队列 ArrayBlockingQueue 的原理。
类图结构
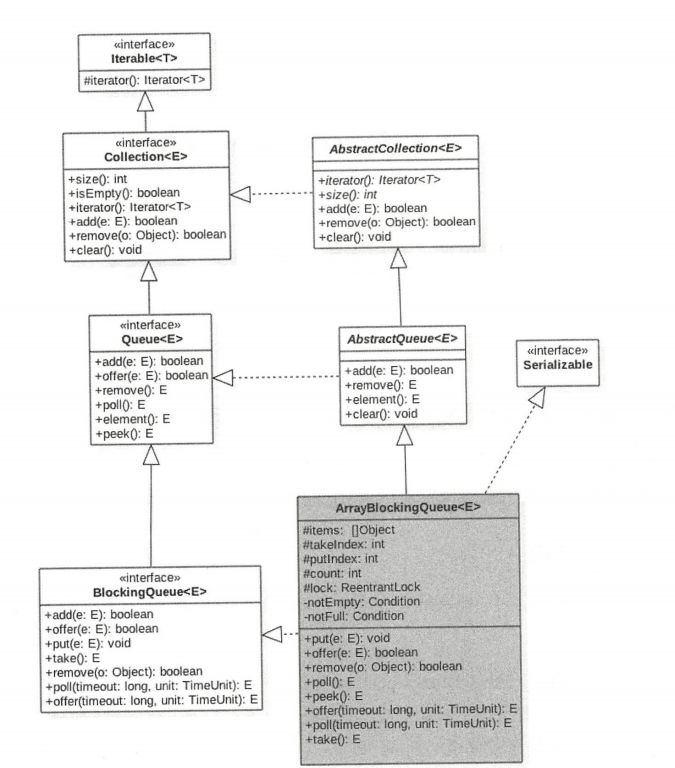
由该图可以看出,**ArrayBlockingQueue 的内部有一个数组 items,用来存放队列元素,putindex 变量表示入队元素下标,takeIndex 是出队下标,count 统计队列元素个数。从定义可知,这些变量并没有使用 volatile 修饰,这是因为访问这些变量都是在锁块内,而加锁已经保证了锁块内变量的可见性了。另外有个独占锁 lock 用来保证出、入队操作的原子性,这保证了同时只有一个线程可以进行入队、出队操作**。另外 notEmpty、notFull 条件变量用来进行出、入队的同步。
另外,由于 ArrayBlockingQueue 是有界队列,所以构造函数必须传入队列大小参数。
public ArrayBlockingQueue(int capacity) { |
由以上代码可知,在默认情况下使用 ReentrantLock 提供的非公平独占锁进行出、入队操作的同步。
原理介绍
offer操作
向队列尾部插入一个元素,如果队列有空闲空间则插入成功并返回 true,如果队列已满则丢弃当前元素然后返回 false。如果 e 元素尾 null 则抛出 NullPointerException 异常。另外该方法是不阻塞的。
public boolean offer(E e) { |
void enqueue(E x)
private void enqueue(E x) { |
如上代码首先把当前元素放入 items 数组,然后计算下一个元素应该存放的下标位置,并递归元素个数计数器,最后激活 notEmpty 的条件队列中因为调用 take 操作而被阻塞的一个线程。这里由于再操作共享变量 count 前加了锁,所以不存在内存不可见问题,加过锁后获取的共享变量都是从主存获取的,而不是从 CPU 缓存或者寄存器获取。
put操作
向队列尾部插入一个元素,如果队列有空闲则插入后直接返回 true,如果队列已满则阻塞当前线程直到队列有空闲并插入成功后返回 true,如果在阻塞时被其他线程设置了中断标志,则被阻塞线程会抛出 IntrruptedException 异常而返回。另外,如果 e 元素为 null 则抛出 NullPointerException 异常。
public void put(E e) throws InterruptedException { |
poll操作
从队列头部获取并移除一个元素,如果队列为空则返回 null,该方法是不阻塞的。
public E poll() { |
E dequeue()
private E dequeue() { |
由以上代码可知,首先获取当前对头元素并将其保存到局部变量,然后重置对头元素为 null,并重新设置对头下标,递减元素计数器,最后发送信号激活 notFull 的条件队列里面一个因为调用 put 方法而被阻塞的线程。
take操作
获取当前队列头部元素并从队列里面移除它。如果队列为空则阻塞当前线程直到队列不为空然后返回元素,如果在阻塞时被其他线程设置了中断标志,则被阻塞线程会抛出 InterruptedException 异常而返回。
public E take() throws InterruptedException { |
take 操作与 poll 相比只是代码(2)不同。在这里如果队列为空则把当前线程挂起后放入 notEmpty 的条件队列,等其他线程调用 notEmpty.signal() 方法后再返回。
peek操作
获取队列头部元素但是不从队列里面移除它,如果队列为空则返回 null,该方法是不阻塞的。
public E peek() { |
peek 的实现更简单,首先获取独占锁,然后从数组 items 中获取当前对头下标的值并返回,在返回前释放获取的锁。
size 操作
计算当前队列元素个数
public int size() { |
size 操作比较简单,获取锁后直接返回 count,并在返回前释放锁。这里因为 count 没有被 volatile 关键字修饰为了保证内存的可见性,所以这里在获取 count 值时加了锁。
小结
ArrayBlockingQueue 通过全局独占锁实现了同时只能一个线程进行入队或者出队操作,这个锁的粒度比较大,有点类似于在方法上添加 synchronized 的意思。其中 offer 和 poll 操作通过简单的加锁进行入队、出队操作,而 put、take 操作则使用条件变量实现了,如果队列满则等待,如果队列空则等待,然后分别在出队和入队操作中发送信号激活等待线程实现同步。另外相比 LinkedBlockingQueue,ArrayBlockingQueue 的 size 操作的结果是精确的,因为计算前加了全局锁。
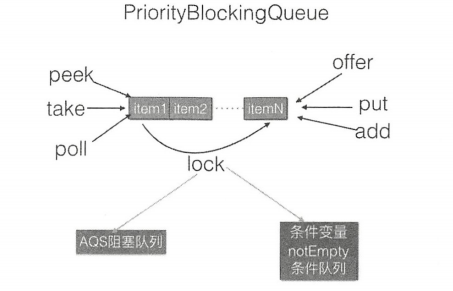
PriorityBlockingQueue 原理探究
介绍
PrirityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高的或者最低的元素。其内部是使用平衡二叉树堆实现的,所以直接遍历队列元素不保证有序。默认使用对象的 compareTo 方法提供比较规则,如果你需要自定义比较规则则可以自定义 comparators。
类图结构
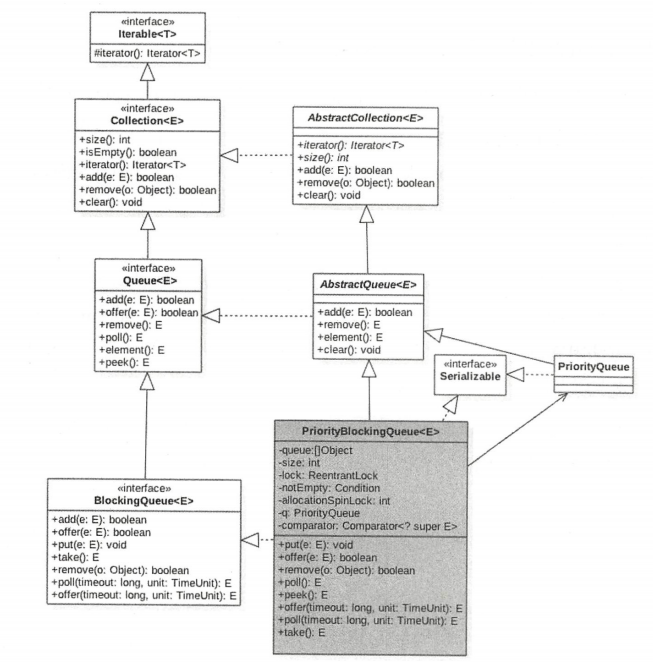
由图可知,PriorityBlockingQueue 内部有一个数组 queue,用来存放队列元素,size 用来存放队列元素个数。allocationSpinLock 是个自旋锁,其使用 CAS 操作来保证同时只有一个线程可以扩容队列,状态为 0 或者 1,其中 0 表示当前没有进行扩容,1 表示当前正在扩容。
由于这是一个优先级队列,所以有一个比较器 comparator 用来比较大小。lock 独占锁对象用来控制同时只能有一个线程可以进行入队、出队操作。notEmpty 条件变量用来实现 take 方法阻塞模式。这里没有 notFull 条件变量是因为这里的 put 操作时非阻塞的,之所以要设计为非阻塞的,是因为这是无界队列。
在如下构造函数种,默认队列容量为 11,默认比较器为 null,也就是使用元素的 compareTo 方法进行比较来确认元素的优先级,这意味着队列元素必须实现 Comparable 接口。
private static final int DEFAULT_INITIAL_CAPACITY = 11; |
原理介绍
offer操作
offer 操作的作用是在队列中插入一个元素,所以一直返回 true。
public boolean offer(E e) { |
以上代码的主流程比较简单,下面主要看看如何进行扩容和在内部建堆。首先看下面的扩容逻辑。
private void tryGrow(Object[] array, int oldCap) { |
tryGrow的作用是扩容。这里为啥在扩容前要先释放锁,然后使用CAS控制只有一个线程可以扩容成功?其实这里不先释放锁,也是可行的,也就是在整个扩容期间一直持有锁,但是扩容是需要花时间的,如果扩容时还占用锁那么其他线程在这个时候是不能进行出队和入队操作的,这大大降低了并发性。所以为了提高性能,使用CAS控制只有一个线程可以进行扩容,并且在扩容前释放锁,让其他线程可以进行入队和出队操作。
spinlock 锁使用 CAS 控制只有一个线程可以进行扩容,CAS 失败的线程会调用 Thread.yield() 让出 CPU,目的是让扩容线程扩容后优先调用 lock.lock 重新获取锁,但是这得不到保证。有可能 yield 的线程在扩容线程完成前已经退出,并执行代码(6)获取到了锁,这时候获取到锁的线程发现 newArray 为 null 执行到 offer 中的代码(1)。如果当前数组扩容还没完毕,当前线程会再次调用 tryGrow 方法,然后释放锁,这又给扩容线程获取锁提供了机会,如果这个时候扩容线程还没有扩容完毕,则当前线程释放锁后又调用 yield 方法让出 CPU。所以当扩容线程进行扩容时,其他线程原地自旋通过代码(1)检查当前扩容是否完毕,扩容完毕才会退出代码(1)的循环。
扩容线程扩容完毕后会重置自旋锁变量 allocationSpinLock 为 0,这里并没有使用 UNSAFE 方法的 CAS 进行设置是因为同时只可能有一个线程获取到该锁,并且 allocationSpinLock 被修饰为了 volatile 的。当扩容线程扩容完毕后会执行代码(6)获取锁,获取锁后复制当前 queue 里面的元素到新数组。
然后看下面的具体建堆法。
private static <T> void siftUpComparable(int k, T x, Object[] array) { |
下面用图来解释上面算法过程,假设队列初始化容量为 2,创建的优先级队列的泛型参数为 Integer。
I. 首先调用队列的 offer(2) 方法,希望向队列插入元素 2 ,插入前队列状态如下所示:

首先执行代码(1),从图中的变量值可知判断结果为 false,所以紧接着执行代码(2)。由于 k=n=size=0,
,所以代码(7)的判断结果为 false,因此会执行代码(8)直接把元素 2 入队。最后执行代码(9)将 size 的值加 1,这时候队列的状态如下所示:

II. 第二次调用队列的 offer(4) 时,首先执行代码(1),从图中的变量值可知判断结果为 false,所以执行代码(2)。由于 k = 1,所以进入 while 循环,由于 parent=0;e=2;key=4;默认元素比较器使用元素的 compareTo 方法。可知 key > e,所以执行 break 退出 siftUpComparable 中的循环,然后把元素存到数组下标为 1 的地方。最后执行代码(9)将 size 的值加 1,这时候队列状态如下所示:

III. 第三次调用队列的 offer(6) 时,首先执行代码(1),从图中的变量值知道,这时候判断结果为 true,所以调用 tryGrow 进行数组扩容。由于 2<64,所以执行 newCap = 2+(2+2)= 6,然后创建新数组并复制,之后调用 siftUpComparable 方法。由于 k=2>0,故进入 while 循环,由于 parent=0;e=2;key=6;key>e,所以执行 break 后退出 while 循环,并把元素 6 放到数组下标为 2 的地方。最后将 size 的值加 1,现在队列状态如下所示:

IV. 第四次调用队列的 offer(1) 时,首先执行代码(1),从图中的变量值知道,这次判断结果为 false,所以执行代码(2).由于 k=3,所以进入 while 循环,由于 parent = 1;e=4;key=1;key<e,所以把元素 4 复制到数组下标为 3 的地方。然后执行 k=1,再次循环,发现 e=2;key=1,key<e,所以复制元素 2 到数组下标 1 处,然后k=0退出循环。最后把元素 1 存放到下标为 0 的地方,现在的状态如下所示:

这时候二叉数堆的树形图如下所示。
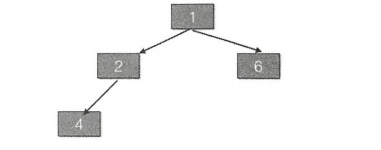
由此可见,堆的根元素是 1,也就是这个一个最小堆,那么当调用这个优先级队列的 poll 方法时,会一次返回堆里面值最小的元素。
poll操作
poll 操作的作用是获取队列内部堆树的根节点元素,如果队列为空,则返回 null。
public E poll() { |
如上代码所示,在进行出队操作时要先加锁,这意味着,当前线程再进行出队操作时,其他线程不能再进行入队和出队操作,但是前面再介绍 offer 函数时介绍过,这时候其他线程可以进行扩容。下面看下具体执行出队操作的 dequeue 方法的代码:
private E dequeue() { |
如上代码中,最重要的是,去掉堆的根节点后,如何使用剩下的节点重新调整一个最大或者最小堆。下面我们查看 siftDownComparable 的实现。
private static <T> void siftDownComparable(int k, T x, Object[] array, |
同样下面我们结合图来介绍调整堆的算法过程。此时队列中的元素序列为1、2、6、4。
I. 第一次调用队列的 poll 方法时,首先执行代码(1)和代码(2),这时候变量 size=4;n=3;result=1;x=4;此时队列状态如下所示。

然后执行代码(3)调整堆后队列状态为

II. 第二次调用队列的 poll() 方法时,首先执行代码(1)和 代码(2),这时候变量 size=3;n=2;result=2;x=6; 此时队列的状态为

然后执行代码(3)调整堆后队列状态为

III. 第三次调用队列的 poll() 方法时,首先执行代码(1)和 代码(2),这时候变量 size=2;n=1;result=4;x=6; 此时队列的状态为

然后执行代码(3)调整堆后队列状态为

IV. 第四次直接返回元素 6。
siftDownComparable
首先介绍下堆调整的思路。由于队列数组第 0 个元素为树根,因此出队时要移除它。这时数组就不再是最小的堆了,所以需要调整堆。 具体从被移除的树根的左右子树中找一个最小的值来当树根,左右子树又会找自己左右子树里面的那个最小值,这是一个递归过程,直到树叶节点结束递归。
下面我们结合图来说明,假如当前队列内容如下:

其对应的二叉堆树为:
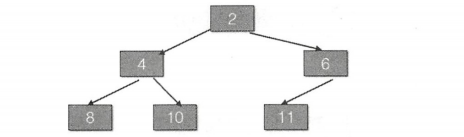
这时候如果调用了 poll(),那么 result = 2;x=11,并且队列末尾的元素被设置为 null,然后对于剩下的元素,调整堆的步骤如下图所示:
图(1)中树根的 leftChildVal = 4;rightChildVal = 6;由于 4<6,所以 c=4。然后由于 11>4,也就是 key>c,所以使用元素 4 覆盖树根节点的值,现在堆对应的树如图(2)所示。
然后树根的左子树树根的左右孩子节点中的 leftChildVal = 8;rightChildVal = 10;由于 8<10,所以 c=8。然后由于 11>8,也就是 key > c,所以元素 8 作为树根左子树的根节点,现在树的形状如图(3)所示。这时候判断是否 k<half,结果为 false,所以退出循环。然后把 x=11 的元素设置到数组下标为 3 的地方,这时候堆树如图(4)所示,至此调整堆完毕。siftDownComparable 返回的 result=2,所以 poll 方法也返回了。
put操作
put 操作内部调用的是 offer 操作,由于是无界队列,所以不需要阻塞。
public void put(E e) { |
take操作
take 操作的作用是获取队列内部堆树的根节点元素,如果队列为空则阻塞,如以下代码所示。
public E take() throws InterruptedException { |
size操作
计算队列元素个数。如下代码在返回 size 前加了锁,以保证调用 size() 方法时不会有其他线程进行入队和出队操作。另外,由于 size 变量没有被修饰为 volatile 的,所以这里加锁也保证了在多线程下 size 变量的内存可见性。
public int size() { |
小结
如下图,PriotityBlockingQueue 类似与 ArrayBlockingQueue,在内部使用一个独占锁来控制同时只有一个线程可以进行入队和出队操作。另外,前者只是用了一个 notEmpty 条件变量而没有使用 notFull,这时因为前者是无界队列,执行 put 操作时永远不会处于 await 状态,所以也不需要被唤醒。而 take 方法是阻塞方法,并且是可被中断的。当需要存放有优先级的元素时该队列比较有用。
DelayQueue 原理探究
DelayQueue 并发队列是一个无界阻塞延迟队列,队列中的每个元素都有个过期时间,当从队列获取元素时,只有过期元素才会出队列。队列头元素时最快要过期的元素。
类图结构
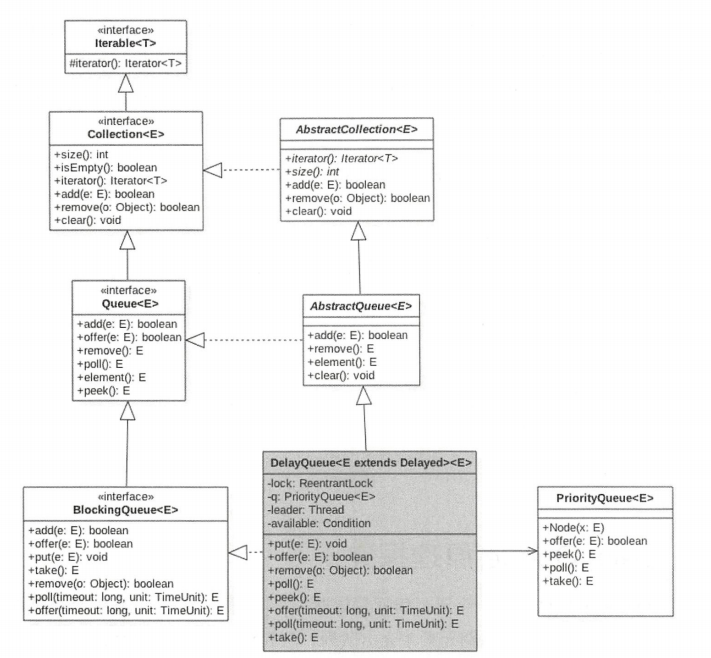
由上图可知,DelayQueue 内部使用 PriorityQueue 存放数据,使用 ReentrantLock 实现线程同步。另外队列里面的元素要实现 Delayed 接口,由于每个元素都有一个过期时间,所以要实现获知当前元素还剩下多少时间就过期了的接口,由于内部使用给优先级队列来实现,所以要实现元素之间相互比较的接口。
public interface Delayed extends Comparable<Delayed> { |
在如下代码中,条件变量 available 与 lock 锁是对应的,其目的是为了实现线程间同步。
private final Condition available = lock.newCondition(); |
其中 leader 变量的使用 Leader-Follower 模式的变体,用于尽量减少不必要的线程等待。当一个线程调用队列的 take 方法变为 leader 线程后,他会调用条件变量 available.awaitNanos(delay) 等待 delay 时间,但是其他线程(follower 线程)则会调用 available.await() 进行无限等待。leader 线程延迟时间过期后,会退出 take 方法,并通过调用 availbale.signal() 方法唤醒一个 follower 线程,被唤醒的 follower 线程被选举为新的 leader 线程。
主要函数原理讲解
offer操作
插入元素到队列,如果插入元素为 null 则抛出 NullPointerException 异常,否则由于是无界队列,所以一定返回 true。插入元素要实现 Delayed 接口。
public boolean offer(E e) { |
take操作
获取并移除延迟队列里面延迟时间过期的元素,如果队列里面没有过期元素则等待。
public E take() throws InterruptedException { |
如上代码首先获取独占锁 lock 假设线程 A 第一次调用队列的 take() 方法时队列为空,则执行代码(1)后 first = null ,所以会执行代码(2)。 把当前线程放入 available 的条件队列里阻塞等待。
当有另外一个线程 B 执行 offer(item) 方法并添加元素到队列是,假设此时没有其他线程执行入队操作,则线程 B 添加的元素是队首元素,那么执行 q.peek()。
e 这时候就会重置 leader 线程为 null,并且激活条件队列里面的一个线程。此时线程 A 就会被激活。
线程 A 被激活并循环候重新获取队首元素,这时候 first 就是线程 B 新增的元素,可知这时候 first 不为 null,则调用 first.getDelay(TimeUnit.NANOSECONDS) 方法查看该元素还剩余多少时间就要过期,如果 delay <=0 则说明已经过期,那么直接出队返回。否则查看 leader 是否为空,不为 null 则说明其他线程也在执行 take,则把该线程放入条件队列。如果这时候 leader 为 null,则选取当前线程 A 为 leader 线程,然后执行代码(5)等待 delay 时间(这期间该线程会释放锁,所以其他线程可以 offer 添加元素,也可以 take 阻塞自己),剩余过期时间到后,线程 A 会重新竞争得到锁,然后重置 leader 线程为 null,重新进入循环,这时候就会发现对头的元素已经过期了,则会直接返回对头元素。
在返回前执行 finally 块里面的代码(7),代码(7)执行结果为 true 则说明当前线程从队列溢出过期元素候,又有其他线程执行了入队操作,那么这时候调用条件变量的 signal 方法,激活条件队列里面的等待线程。
poll操作
获取并移除队头过期元素,如果没有过期元素则返回 null。
public E poll() { |
size操作
计算队列元素个数,包含过期的和没过期的。
public int size() { |
案例介绍
public class DelayQueueTest { |
如上代码首先创建延迟任务 DelayedEle 类,其中 delayTime 表示当前任务需要延迟多少 ms 时间过期,expire 则是当前时间的 ms 值加上 delayTime 的值。另外,实现了 Delayed 接口,实现了 long getDelay(TimeUnit unit) 方法用来获取当前元素还剩下多少时间过期,实现了 int compareTo(Delayed 0) 方法用来决定优先级队列元素的比较规则。
在 test 函数内创建了一个延迟队列,然后使用随机数生成器生产了 10 个延迟任务,最后通过循环依次获取延迟任务,并打印。
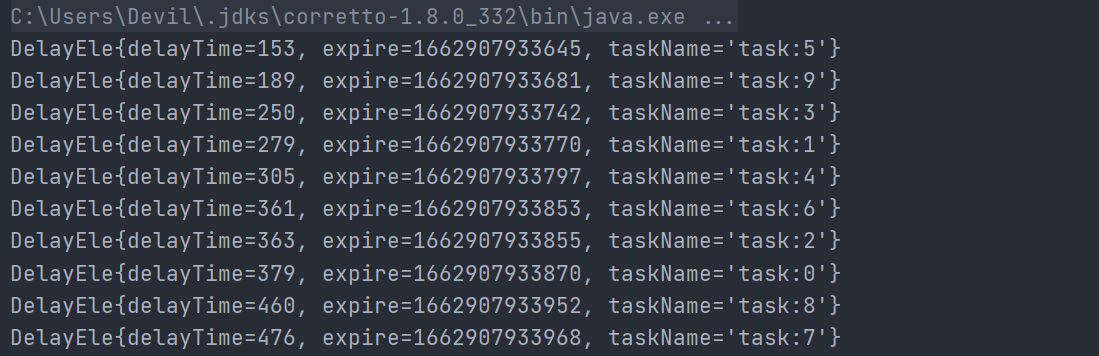
可见出队的顺序和 delay 时间有关,而与创建任务的顺序无关。
小结
本节讲解了 DelayQueue 队列,其内部使用 PriorityQueue 存放数据,使用 ReentrantLock 实现线程同步。另外队列里面的元素要实现 Delayed 接口。
第八章 Java 并发包中线程池 ThreadPoolExecutor 原理探究
介绍
线程池主要解决了两个问题:一是当执行大量异步任务时线程池能够提供较好的性能。在不使用线程池时,每个需要执行异步任务时直接 new 一个线程来运行,而线程的创建和销毁是需要开销的。线程池里面的线程是可复用的,不需要每次执行异步任务时都重新创建和销毁线程。二是线程池提供了一种资源限制和管理的手段,比如可以限制线程的个数,动态新增线程等。每个 ThreadPoolExecutor 也保留了一些基本的统计数据,比如当前线程池完成任务数目等。
另外,线程池也提供了许多可调参数和可扩展性接口,以满足不同情景的需要,程序员可以使用更方便的 Executors 的工厂方法(阿里巴巴编程手册不推荐使用,他希望通过 ThreadPoolExecutor 来创建线程池,让使用者更加了解),比如 newCachedThreadPool(线程池线程个数最多可达 Integer.MAX_VALUE,线程自动回收)、newFixedThreadPool(固定大小的线程池)和 newSingleThreadExecurtor(单个线程)等来创建线程池,当然用户还可以自定义。
类图介绍
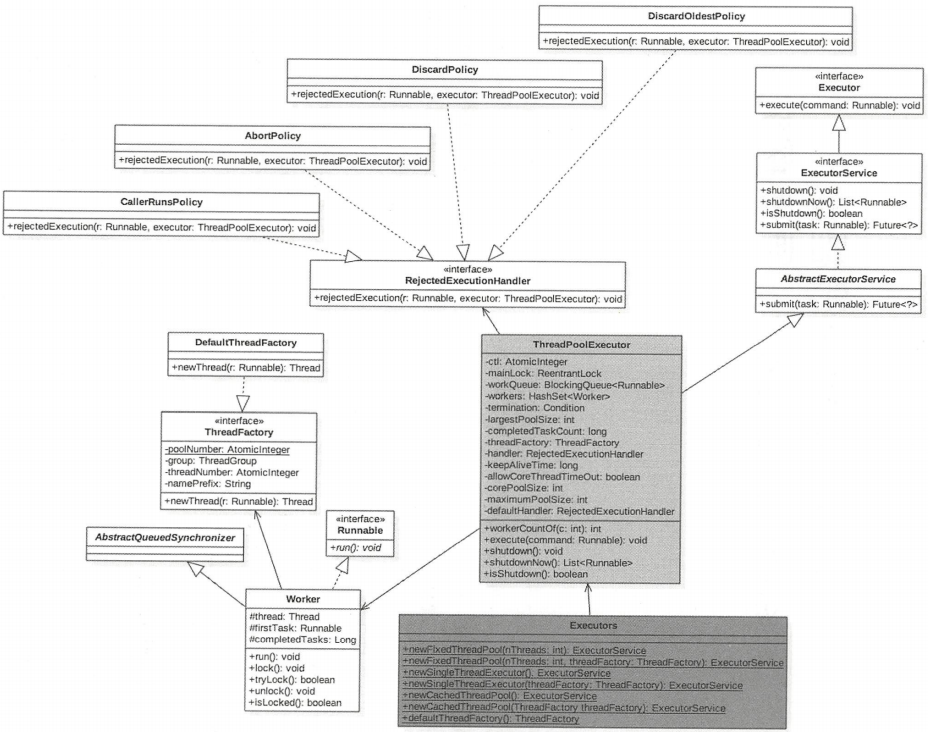
如图所示,Executors 其实是一个工具类,里面提供了好多静态方法,这些方法根据用户选择返回不同的线程池实例。ThreadPoolExecutor 继承了 AbstractExecutorService,成员变量 ctl 是一个 Integer 的原子变量,用来记录线程池状态和线程池中线程个数,类似于 ReentrantReadWriteLock 使用一个变量来保存两种信息。
这里假设 Integer 类型是 32 位二进制表示,则其中高三位用来表示线程池状态,后面 29 位用来记录线程池线程个数。
//(高三位)用来记录表示线程池状态,(低29位)用来表示线程个数 |
线程池状态含义如下。
- RUNNING:接受新任务并且处理阻塞队列里面的任务。
- SHUTDOWN:拒绝新任务但是处理阻塞队列里面的任务。
- STOP:拒绝新任务并且抛弃阻塞队列里面的任务,同时会中断正在处理的任务。
- TIDYING:所有任务都执行完(包含阻塞队列里面的任务)后当前线程池活动线程数为 0,将要调用 terminated 方法
- TERMINATED:终止状态。terminated 方法调用完成以后的状态。
线程池状态转化列举如下。
- RUNNING -> SHUTDOWN:显示调用 shutdown() 方法,或者隐式调用了 finalize() 方法里面的 shutdown()方法。
- RUNNING 或 SHUTDOWN -> STOP:显示调用
shutdownNow()方法时。- SHUTDOWN -> TIDYING:当前线程池为空时。
- TIDYING -> TERMINATED:当
terminated()hook方法执行完成时。
线程池核心参数如下。
corePoolSize:线程池核心线程个数。workQueue:用于保存等待执行的任务的阻塞队列,比如基于数组的有界ArrayBlockingQueue、基于链表的LinkedBlockingQueue、最多只有一个元素的同步队列SynchronousQueue及优先级队列PriorityBlockingQueue等。maximunPoolSize:线程池最大线程数量。ThreadFactory:创建线程的工厂。RejectedExecutionHeandler:饱和拒绝策略,当队列满并且线程个数达到maximunPoolSize后采取的策略,比如AbortPolicy(抛出异常)、CallerRunsPolicy(使用调用者所在线程来运行任务)、DiscardOldestPolicy(调用 poll 丢弃一个任务,执行当前任务)及DiscardPolicy(默默丢弃,不抛出异常)。keeyAliveTime:存活时间。如果当前线程池中的线程数量比核心线程数量多,并且是闲置状态,则这些闲置的线程能存活的最大时间。TimeUnit:存活时间的时间单位。
线程类型如下。
newFixedThreadPool:创建一个核心线程个数和最大线程个数都为nThreads的线程池,并且阻塞队列长度为Integer.MAX_VALUE。keeyAliveTime = 0说明只要线程个数比核心线程个数多并且当前空闲则回收。
public static ExecutorService newFixedThreadPool(int nThreads) { |
newSingleThreadExecutor:创建一个核心线程个数和最大线程个数都为 1 的线程池,并且阻塞队列长度为Integer.MAX_VALUE。keeyAliveTime=0说明只要线程个数比核心线程个数多并且当前空闲则回收。
public static ExecutorService newSingleThreadExecutor() { |
newCachedThreadPool:创建一个按需创建线程的线程池,初始线程个数为 0,最多线程个数为Integer.MAX_VALUE,并且阻塞队列为同步队列。keeyAliveTime = 60说明只要当前线程在 60s 内空闲则回收,这个类型的特殊之处在于,加入同步队列的任务会被马上执行,同步队列里面最多只有一个任务。
public static ExecutorService newCachedThreadPool() { |
如上 ThreadPoolExecutor 类图所示,其中 mainLock 是独占锁,用来控制新增 Worker 线程操作的原子性。termination 是该锁对应的条件队列,在线程调用 awaitTermination 时用来存放阻塞的线程。
Worker 继承 AQS 和 Runnable 接口,是具体承接任务的对象。Worker 继承了 AQS,自己实现了简单不可重入独占锁,其中 state = 0 表示锁未被获取状态,state=1 表示锁已经被获取的状态,state=-1 是创建 Worker 时默认的状态,创建时状态设置为 -1 是为了避免该线程在运行 runWorker() 方法前被中断,下面会具体讲解。其中变量 firstTask 记录该工作线程执行的第一个任务,thread 是具体执行任务的线程。
DefaultThreadFactory 是线程工厂,newThread 方法是对线程的一个装饰。其中 poolNumber 是个静态的原子变量,用来统计线程工厂的个数,threadNumber 用来记录每个线程功能创建了多少线程,这两个值也作为线程池和线程的名称的一部分。
源码分析
public void execute(Runnable command)
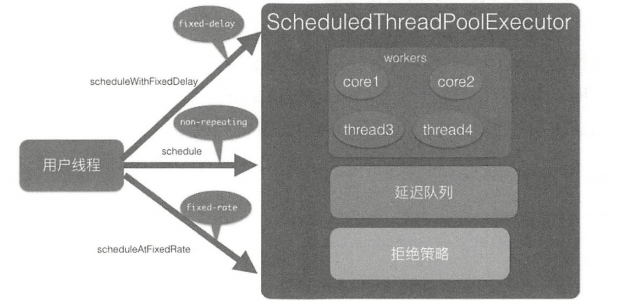
execute 方法的作用是提交任务 command 到线程池进行执行。用户线程提交到线程池的模型如图所示
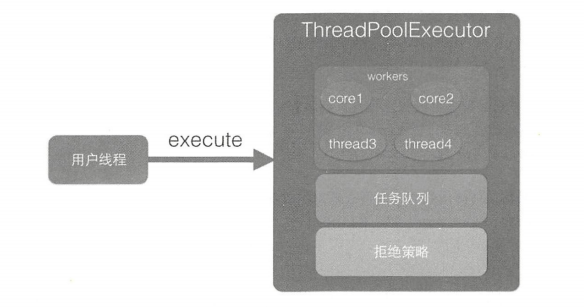
从该图可以看出,ThreadPoolExecutor 的实现实际是一个生产消费模型,当用户添加任务到线程池时相当于生产者生产元素,workers 线程工作集 中的线程直接执行任务或者从任务队列里面获取任务时则相当于消费者消费元素。
用户线程提交任务的 execute 方法的具体代码如下。
public void execute(Runnable command) { |
代码(3)判断如果当前线程池中线程个数小于 corePoolSize,会向 workers 里面新增一个核心线程(core 线程)执行该任务。
如果当前线程池中线程个数大于等于 corePoolSize 则执行代码(4)。如果当前线程池处于 RUNNING 状态则添加当前任务到任务队列。这里需要判断线程池状态是因为有可能线程池已经处于非 RUNNING 状态,而在非 RUNNING 状态下是要抛弃新任务的。
如果向任务队列添加任务成功,则代码(4.2)会对线程池状态进行二次校验,这是因为添加恩物到任务队列后,执行代码(4.2)前有可能线程池的状态已经变化了。这里进行二次校验,如果当前线程池状态不是 RUNNING 了则把任务从任务列表移除,移除后执行拒绝策略;如果二次校验通过,则执行校验通过,则执行代码(4.3)重新判断当前线程池里面是否还有线程,如果没有则新增一个线程。
如果代码(4)添加任务失败,则说明任务队列已满,那么执行代码(5)尝试新开启线程(上图中的 thread3、thread4)来执行该任务,如果当前线程池中线程个数>maximumPoolSize 则执行拒绝策略。
下面分析下新增线程的 addWorker 方法。
private boolean addWorker(Runnable firstTask, boolean core) { |
代码较长,主要分为两个部分:第一部分双重循环的目的是通过 CAS 操作增加线程数;第二部分主要是把并发安全的任务添加到 workers 里面,并且启动任务执行。
首先来分析第一部分的代码(6)
//(6) 检查队列是否值在必要时为空 |
展开 ! 运算后等价于
rs>=SHUTDOWN && |
也就是说代码(6)在下面几种情况下会返回 false:
- (I) 当前线程池状态为 STOP、TIDYING 或 TERMINATED。
- (II) 当前线程池状态为 SHUTDOWN 并且已经有了第一个任务。
- (III) 当前线程池状态为 SHUTDOWN 并且任务队列为空。
内层循环的作用是使用 CAS 操作增加线程数,代码(7.1)判断如果线程个数超限则返回 false,否则执行代码(7.2)CAS 操作设置线程个数,CAS 成功则退出双循环,CAS 失败则执行代码(7.3)看当前线程池的状态是否变化了,如果变了,则再次进入外层循环重新获取线程池状态,否则进入内存循环继续进行 CAS 尝试。
执行到第二部分的代码(8)时说明使用 CAS 成功地增加了线程个数,但是现在任务还没开始执行。这里使用全局的独占锁来控制把新增的 Worker 添加到工作集 workers 中。代码(8.1)创建了一个工作线程 Worker。
代码(8.2)获取了独占锁,代码(8.3)重新检查线程池状态,这是为了避免在获取线程前其他线程调用了 shutdown 关闭了线程池。如果线程池已经被关闭,则释放锁,新增线程失败,否则执行代码(8.4)添加工作线程到线程工作集,然后释放锁。代码(8.5)判断如果新增工作线程成功,则启动工作线程。
工作线程 Worker 的执行
用户提交任务到线程池后,由 Worker 来执行。先看下 Worker 的构造函数。
Worker(Runnable firstTask) { |
**构造函数中首先将 Worker 的状态设置为 -1,这是为了避免当前 Worker 在调用 runWorker 方法前被中断(防止任务在执行前被中断)**(当其他线程调用了线程池的 shutdownNow 时,如果 Worker 状态 >= 0 则会中断该线程)。这里设置了线程的状态为 -1,所以该线程就不会被中断了。在如下 runWorker 代码中(开始执行任务),运行代码(9)时会调用 unlock 方法,该方法把 status 设置为了 0 所以这时候调用 shutdownNow 会中断 Worker 线程。
//worker 对象的 run 方法 |
在代码(10)中,如果当前 task == null 或者调用 getTask 从任务队列获取的任务为 null,则跳转到代码(11)执行。如果 task 不为 null 则执行代码(10.1)获取工作线程内部持有的独占锁,然后执行扩展接口代码(10.2)在具体任务执行前做一些事情。最后代码(10.5)统计当前worker 完成了多少任务,并释放锁。
这里在执行具体任务期间加锁(设置 state 为 1),是为了避免在任务运行期间,其他线程调用了 shutdown 后正在执行的任务被中断(shutdown 只会中断当前被挂起的线程)。
代码(11)执行清理任务,其代码如下
private void processWorkerExit(Worker w, boolean completedAbruptly) { |
代码(11.1)中统计线程池完成任务个数,并且统计前加了全局锁。把当前工作线程中完成的任务累加到全局计数器,然后工作集中删除当前 Worker。
代码(11.2)判断如果当前线程池状态时 SHUTDOWN 并且工作队列为空,或者当前线程池状态是 STOP 并且当前线程池里面没有活动线程,则设置线程池状态为 TERMINATED。如果设置为了 TERMINATED 状态,则还需要调用条件变量 termination 的 signlAll() 方法激活所有因为调用线程池的 awaitTermination 方法而被阻塞的线程。
shutdown 操作
调用 shutdown 方法后,线程池就不会再接收新的任务了,但是工作队列里面的任务还是要执行的。该方法会立刻返回,并不等待任务完成后再返回。
public void shutdown() { |
代码(12)检查看是否设置了安全管理器,是则看当前调用 shutdown 命令的线程是否有关闭线程的权限,如果有权限还要看调用线程是否有中断工作线程的权限,如果没有权限则抛出 SecurityException 或者 NullPointerException 异常。
其中代码(13)的内容如下,如果当前线程池的状态 >= SHUTDOWN 则直接返回,否则设置为 SHUTDOWN 状态。
private void advanceRunState(int targetState) { |
代码(14)其设置所有空闲线程的中断标志。这里首先加了全局锁,同时只有一个线程可以调用 shutdown 方法设置中断标志。然后尝试获取 Worker 自己的锁,获取成功则设置中断标志。由于正在执行的任务已经获取了锁,所以正在执行的任务没有被中断。这里的中断的是阻塞到 getTask() 方法并企图从队列里面获取任务的线程,也就是空闲线程。
private void interruptIdleWorkers() { |
tryTerminate() 方法首先使用 CAS 设置当前线程池的状态为 TIDYING,如果设置成功则执行扩展接口 terminated 在线程池状态变为 TERMINATED 前做一些事情,然后设置当前线程池状态为 TERMINATED。最后调用 termination.signalAll() 激活因调用条件变量 termination 的 await 系列方法而被阻塞的所有线程。
shutdownNow 操作
调用 shutdownNow 方法后,线程池就不会再接收新的任务了,并且会丢弃工作队列里面的任务,正在执行的任务会被中断,该方法会立刻返回,并不等待激活的任务执行完成。返回值为这时候队列里面被丢弃的任务列表。
public List<Runnable> shutdownNow() { |
注意:代码(18)处中断所有线程,这里中断的线程包含空闲线程和正在执行任务的线程。
private void interruptWorkers() { |
awaitTermination 操作
当线程调用 awaitTermination 方法后,当前线程会被阻塞,直到线程池状态变为 TERMINATED 才返回,或者等待时间超时才返回。
public boolean awaitTermination(long timeout, TimeUnit unit) |
当线程池状态变为 TERMINATED 时,会调用
termination.signalAll()用来激活调用条件变量 termination 的 await 系列方法被阻塞的所有线程,所以如果在调用awaitTermination之后又调用了 shutdown 方法,并且在 shutdown 内部将线程池状态设置为 TERMINATED,则termination.awaitNanos方法会返回。另外在工作线程 Worker 的
runWorker方法内,当工作线程运行结束后,会调用processWorkerExit方法,在processWorkExit方法内部也会调用tryTerminate方法测试当前是否应该把线程池状态设置为 TERMINATED,如果是,则也会调用termination.signalAll()用来激活调用线程池的awaitTermination方法而被阻塞的线程。而且当等待时间超过后,
termination.awaitNanos也会返回,这时候会重新检查当前线程池状态是否为 TERMINATED,如果是则直接返回,否则继续挂起自己。
线程池的优点
降低资源的消耗
- 通过重复利用已经创建好的线程降低线程的创建和销毁带来的损耗
提高响应速度
- 因为线程池中的线程数没有超过线程池的最大上限时,有的线程处于等待分配任务的状态,当任务来时无需创建新的线程就能执行
提高线程的可管理性
- 线程池会根据当前系统特点对池内的线程进行优化处理,减少创建和销毁线程带来的系统开销。无限的创建和销毁线程不仅消耗系统资源,还降低系统的稳定性,使用线程池进行统一分配
第9章 Java 并发包中 ScheduledThreadPoolExecutor 原理探究
介绍
前面的 ThreadPoolExecutor 只是 Executors 工具类的一部分功能。下面来介绍另外一部分功能,也就是 ScheduledThreadPoolExecutor 的实现,这是一个可以在指定一定延迟时间后或者定时进行任务调度执行的线程池。
类图介绍
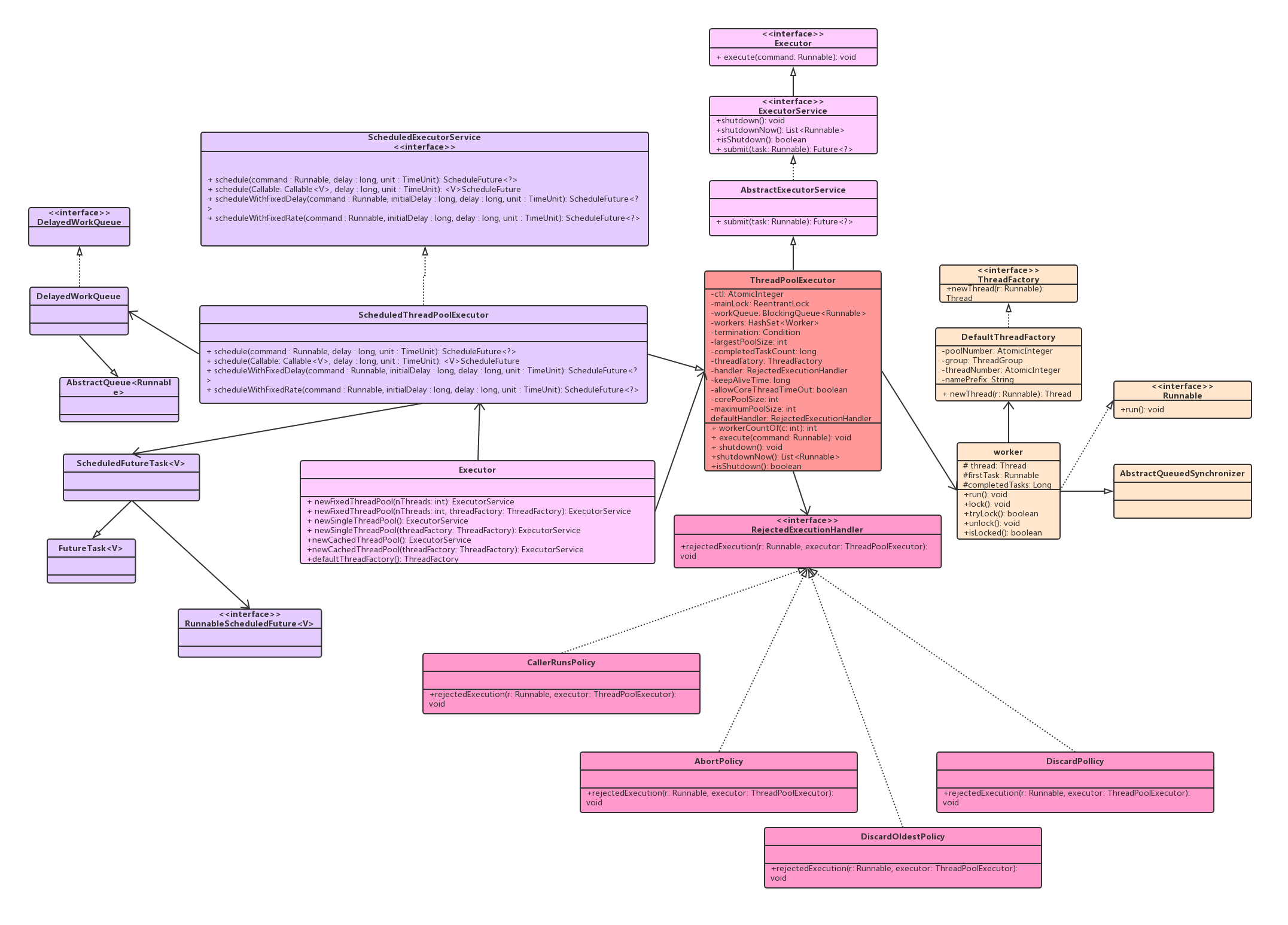
ScheduledThreadPoolExecutor 继承了 ThreadPoolExecutor 并实现了 ScheduledExecutorService 接口。线程池队列是 DelayedWorkQueue,其和 DelayedQueue 类似,是一个延迟队列
ScheduledFutureTask 是具有返回值的任务,继承自 FutureTask。FutureTask 内部有一个变量 state 用来表示任务的状态,一开始状态是 NEW,所有状态为
private static final int NEW = 0; //初始状态 |
可能的任务状态转换路径为
NEW -> COMPLETING -> NORMAL //初始状态->执行中->正常结束
NEW -> COMPLETING -> EXCEPTIONAL //初始状态->执行中->执行异常
NEW -> CANCELLED //初始状态->任务取消
NEW - > INTERRUPTING -> INTERRUPTED //初始状态 -> 被中断中 -> 被中断
ScheduleFutureTask 内部还有一个变量 period 用来表示任务的类型,任务类型如下:
- period=0,说明当前任务是一次性的,执行完毕后就退出了。
- period 为负数,说明当前任务为 fixed-delay 任务,是固定延迟的定时可重复执行任务。
- period 为正数,说明当前任务为 fixed-rate 任务,是固定频率的定时可重复执行任务。
ScheduledThreadPoolExecutor 的一个构造函数如下,由该构造函数可知线程池队列是 DelayWorkQueue
public ScheduledThreadPoolExecutor(int corePoolSize) { |
原理剖析
主要剖析三个重要的函数。
schedule(Runnable command, long delay, TimeUnit unit) 方法
该方法的作用是提交一个延迟执行的任务,任务从提交时间算起延迟单位为 unit 的 delay 时间后开始执行。提交的任务不是周期性惹我你,任务只会执行一次,代码如下。
public ScheduledFuture<?> schedule(Runnable command, |
代码(2)处任务转换。ScheduleFutureTask 是具体放入延迟队列里面的东西。由于是延迟队列,所以 ScheduleFutureTask 实现了 long getDelay(TimeUnit unit) 和 int compareTo(Delayed other) 方法。**triggerTime 方法将延迟时间转换为绝对时间,也就是把当前时间的纳米数加上延迟的纳米数后的 long 型值。** ScheduleFutureTask 的构造函数如下。
ScheduledFutureTask(Runnable r, V result, long ns) { |
在构造函数内部手下调用了父类的 FutureTask 的构造函数,父类 FutureTask 的构造函数如下。
public FutureTask(Runnable runnable, V result) { |
FutureTask 中的任务被转换为 Callable 类型后,被保存到变量 this.callable 里面,并设置 FutureTask 的任务状态为 NEW
然后在 ScheduleFutureTask 构造函数内部设置 time 为上面说的绝对时间。需要注意,这里 period 的值为 0,这说明当前任务为一次性的任务,不是定时反复执行任务。其中 long getDelay(TimeUnit unit) 方法的代码如下(该方法用来计算当前任务还有多少时间就过期了)。
//元素过期算法,装饰后时间-当前时间,就是即将过期剩余时间 |
compareTo(Delayed other) 方法的代码如下:
public int compareTo(Delayed other) { |
compareTo 的作用是加入元素到延迟队列后,在内部建立或调整堆时会使用该元素的 compareTo 方法与队列里面其他元素进行比较,让最快要过期的元素放到队首。所以无论什么时候向队列里面添加元素,队首元素都是最快要过期的元素。
III. 代码(3)将任务添加到延迟队列,delayedExecute 的代码如下。
private void delayedExecute(RunnableScheduledFuture<?> task) { |
IV. 可以看到代码(6)处添加完毕后会再次检查线程池是否被关闭,如果已经被关闭了则从延迟队列中删除刚才添加的任务,但是此时有可能线程池中的线程已经从任务队列里面移除了该任务,也就是该任务已经在执行了,所以需要调用任务的 cancel 方法取消任务。
V. 如果代码(6)判断结果为 false,则会执行代码(7)确保至少有一个线程在处理任务,即使核心线程数 corePoolSize 被设置为 0 。ensurePrestart 的代码如下。
void ensurePrestart() { |
下面我们来看线程池里面的线程如何获取并执行任务。在 ThreadPoolExecutor 里我们说过,具体执行任务的线程是 Worker 线程, Worker 线程调用具体任务的 run 方法来执行。由于这里的任务时 ScheduleFutureTask,所以我们下面看看 ScheduledFutureTask 的 run 方法。
public void run() { |
VI. 代码(8)中的 isPeriodic 的作用是判断当前任务是一次性任务还是可重复执行的任务,isPeriodic 的代码如下。
public boolean isPeriodic() { |
VII. 代码(9)判断当前任务是否应该被取消,canRunInCurrentRunState 的代码如下。
boolean canRunInCurrentRunState(boolean periodic) { |
这里传递的 period 的值为 false,所以 isRunningOrShutdown 的参数为 executeExistingDelayedTasksAfterShutdown。executeExistingDelayedTasksAfterShutdown 默认为 true,表示如果其他线程调用了 shutdown 命令关闭了线程池后,当前任务还是要执行,否则如果为 false,则当前任务要被取消。
VIII. 由于 periodic 的值为 false,所以执行代码(10)调用父类 FutureTask 的 run 方法具体执行任务。FutureTask 的 run 方法的代码如下。
public void run() { |
当任务执行成功则执行(13.2)修改任务状态,set 方法代码如下。
protected void set(V v) { |
在什么时候多个线程会同时执行
CAS将当前任务的状态从 NEW 转换到 COMPLETING?其实当同一个 command 被多次提交到线程池时就会存在这样的情况,因为同一个任务共享一个状态值 state。
如果任务执行失败,则执行代码(13.1)。setException 的代码如下,可见与 set 函数类似。
protected void setException(Throwable t) { |
到这里一次性任务也就执行完毕了。
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) 方法
该方法的作用时,当任务执行完毕后,让其延迟固定时间再次运行(fixed-delay 任务)。其中 initialDelay 表示提交任务后延迟多少时间开始执行任务 command,delay 表示当任务执行完毕后延长多少多少时间后再次运行 command 任务,unit 时 initialDelay 和 delay 的时间单位。任务会一直重复直到任务运行中抛出了异常,被取消了,或者关闭了线程池。scheduleWithFixedDelay 的代码如下。
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, |
将任务添加到延迟队列后线程池会从队列里面获取任务,然后调用 ScheduledFutureTask 的 run 方法执行。由于 period < 0 ,所以 isPeriodic 返回 true,所以执行代码(11)。runAndReset()
protected boolean runAndReset() { |
该代码和 FutureTask 的 run 方法类似,只是任务正常执行完毕后不会设置任务的状态,这样做是为了让任务成为可重复执行的任务。这里多了代码(19),这段代码判断如果当前任务正常执行完毕并且任务状态为 NEW 则返回 ture,否则返回 false。如果返回 true 则执行代码(11.1)的 setNextRunTime 方法设置该任务下一次的执行时间。setNextRunTime 的代码如下。
private void setNextRunTime() { |
总结:fixed-delay 类型任务的执行原理为,当添加一个任务到延迟队列后,等待
initialDelay时间,任务就会过期,过期的任务就会被从队列移除,并执行。执行完毕后,会重新设置任务的延迟时间,然后再把任务放入延迟队列,循环往复。需要注意的是,如果一个任务在执行中抛出了异常,那么这个任务就结束了,但是不影响其他任务的执行。
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) 方法
该方法相对起始时间点以固定频率调用指定的任务(fixed-rate 任务)。当把任务提交到线程池并延迟 initialDelay 时间(时间单位为 unit)后开始执行任务 command。然后从 initialDelay+period 时间点再次执行,而后在 initialDelay + 2 * period 时间点再次执行,循环往复,直到抛出异常或者调用了任务的 cancel 方法取消了 任务,或者关闭了线程池。scheduleAtFixedRate 的原理与 scheduleWithFixedDelay 类似,下面我们讲下他们之间的不同点。
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, |
因为这里 period > 0 所以当前任务执行完毕后,调用 setNextRunTime 设置任务下次执行的时间时执行的是 time+=p 而不再是 time = triggerTime(-p)。
总结:相对于 fixed-delay 任务来说,fixed-rate 方式执行规则为,时间为
initialDelay + n * period时启动任务,但是如果当前任务还没有执行完,下一次要执行的任务时间到了,并不会并发执行,下次要执行的任务会延迟执行,要等到当前任务执行完毕后再执行。
总结
第十章 Java 并发包中线程同步器原理剖析
CountDownLatch 原理剖析
案例介绍
在日常开发中经常需要在主线程中开启多个线程去并行执行任务,并且主线程需要等待所有子线程完毕后再进行汇总的场景。在 CountDownLathch 出现之前一般都使用 join() 方法来实现这一点,但是 join 方法不够灵活,不能够满足不同场景的需求,所以 JDK 开发组提供 CountDownLatch 这个类,我们前面介绍的例子使用 CountDownLatch 会更优雅。
public class JoinCountDownLatch { |
输出结果如下。

主线程调用 countDownLatch.await() 方法后会被阻塞。子线程执行完毕后调用 countDownLatch.await() 方法让 countDownLatch 内部的计数器减一,所有子线程执行完毕并调用 countDown() 方法后计数器会变为 0,这时候主线程的 await() 方法才会返回。
其实上面的代码还不够优雅,在项目实践中一般都避免直接操作线程,而是使用 ExecutorService 线程池来管理。使用 ExecutorService 时传递的参数是 Runnable 或者 Callable 对象,这时候你没有办法直接调用这些线程的 join() 方法,这就需要选择使用 CountDownLatch 了。将上面代码修改为如下:
public class JoinCountDownLatch2 { |
输出结果如下。

总结:
CountDownLatch与join方法的区别。一个区别是,调用一个子线程的join()方法后,该线程会一直被阻塞直到子线程运行完毕,而CountDownLatch则使用计数器来运行子线程运行完毕或者在运行中递减计数,也就是CountDownLatch可以在子线程运行的任何时候让 await 方法返回而不一定必须等到线程结束。另外,使用线程池来管理线程时一般都是直接添加 Runnable 到线程池,这时候就没办法再调用线程的 join 方法了,就是说countDownLatch相比 join 方法让我们对线程同步有更灵活的控制。
实现原理探究
CountDownLatch 的内部有一个计数器,这个计数器是递减的。下面通过源码看看 JDK 开发组在何时初始化计数器,在何时递减计数器,当计数器变为 0 时做了什么操作,多个线程是如何通过计时器实现同步的。
类图结构
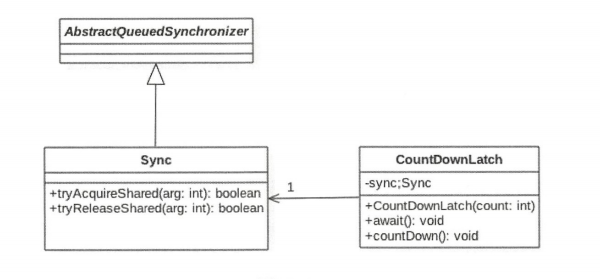
从类图可以看出,CountDownLatch 时使用 AQS 实现的。通过下面的构造参数,你会发现,实际是把计数器的值赋给了 AQS 的状态变量 state,也就是这里使用 AQS 的状态值来表示计数器值。
public CountDownLatch(int count) { |
下面来研究 CountDownLatch 中的几个重要方法的原理。
void await()方法
当线程调用 CountDownLatch 对象的 await 方法后,当前线程会被阻塞,直到以下情况之一发送才会返回。
- 当所有线程都调用了
CountDownLatch对象的countDown方法后,也就是计数器的值为 0 时; - 其他线程调用了当前线程的 interrupt() 方法中断了当前线程,当前线程会抛出
InterruptedException异常,然后返回。
//CountDownLatch 的 await 方法 |
CountDownLatch 的 await 方法委托了 sync 调用了 AQS 的 acquireSharedInterruptibly 方法,后者的代码如下:
// AQS 获取共享资源时可被中断的方法 |
boolean await(long timeout, TimeUnit unit)
当线程调用了 CountDownLatch 对象的该方法后,当前线程会被阻塞,直到下面的情况之一才会返回:
- 当所有线程都调用了
CountDownLatch对象的countDown方法后,也就是计数器的值为 0 时; - 设置的
timeout时间到了,因为超时而返回 false; - 其他线程调用了当前线程的 interrupt() 方法中断了当前线程,当前线程会抛出
InterruptedException异常,然后返回。
public boolean await(long timeout, TimeUnit unit) |
void countDown()方法
线程调用该方法后,计数器的值递减,递减后如果计数器值为 0 则唤醒所有因为调用 await 方法而被阻塞的线程,否则什么也不做。
public void countDown() { |
//AQS 的方法 |
代码(2)使用 CAS 将计数器最后一个线程调用的 countdown 方法,那么该线程除了让计数器值减 1 外,还需要唤醒因调用 CountDownLatch 的 await 方法而被阻塞的线程,具体是调用 AQS 的 doReleaseShared 方法来激活阻塞的线程。这里代码(1)是为了防止当计数器值为 0 后,其他线程又来调用 countDown。
long getCount()方法
获取当前计数器的值,也就是 AQS 的 state 的值,一般在测试时使用该方法。
public long getCount() { |
由如上代码可知,在其内部还是调用的 AQS 的 getState 方法来获取 state 的值(计数器当前值)。
回环屏障 CyclicBarrier 原理探究
前面介绍的 CountDownLatch 在解决多个线程同步问题方面相对于调用线程的 join 方法已经有了不少优化,但是 CountDownLatch 的计数器是一次性的,也就是等到计数器值变为 0 后,再调用 CountDownLatch 的 await 和 countDown 方法都会立刻返回,这就起不到线程同步的效果了。所以为了满足计数器可以重置的需要,JDK 开发组提供了 CyclicBarrier 类,并且 CyclicBarrier 类的功能不限于 CountDownLatch 的功能。从字面意思理解,CyclicBarrier 是回环屏障的意思,它可以让一组线程全部达到一个状态后再全部同时执行。这里之所叫回环是因为当所有等待线程执行完毕,并重置 CyclicBarrier 的状态后它可以被重用。之所以叫屏障是因为线程调用 await 方法后就会被阻塞,这个阻塞点就称为屏障点,等所有线程都调用了 await 方法后,线程们就会冲破屏障,继续向下运行。
案例介绍
下面的例子中,我们实现的是,使用两个线程去执行一个被分解的任务A,当两个线程把自己的任务都执行完毕后再对他们的结果进行汇总处理。
public class CyclicBarrierTest1 { |
输出结果如下。

如上代码创建一个
CyclicBarrier对象,其构造函数第一个参数为计数器初始值,第二个参数 Runnable 是当前计数器值为 0 时需要执行的任务。在 main 函数里面首先创建了一个大小为 2 的线程池,然后添加两个子任务到线程池,每个子任务在执行完自己逻辑后会调用 await 方法。一开始计数器值为 2 ,当一个线程调用 await 方法时,计数器值会递减为 1 由于此时计数器值不为 0,所以当前线程就到了屏障点而被阻塞。然后第二个线程调用 await 时,会进入屏障,计数器值也会递减,现在计数器值为 0,这是就会去执行CyclicBarrier构造函数中的任务,执行完毕后退出屏障点,并且唤醒被阻塞的第二个线程,这时候第一个线程也会退出屏障点继续向下运行。
上面的例子说明了多个线程之间是相互等待的,假如计数器值为 N,那么随后调用 await 方法的 N-1 个线程都会因为到达屏障点而被阻塞,当第 N 个线程调用 await 后,计数器值为 0 了,这时候第 N 个线程才会发出通知唤醒前面的 N-1 个线程。也就是全部线程都到达屏障点时才能一块继续向下执行。这说明 使用 CountDownLatch 也可以得到类似的输出结果。
下面举个例子来说明 Cyclicbarrier 的复用性
假设一个任务由阶段 1、阶段 2 和阶段 3 组成,每个线程都串行地执行阶段 1、阶段 2 和阶段 3 ,当多个线程执行该任务时,必须要保证所有线程的阶段 1 全部完成后才能进入阶段 2 执行,阶段 3 同理
public class CyclicBarrierTest2 { |
输出结果如下。

如上代码中,每个子线程再执行完阶段 1 后都调用了 await 方法,等到所有线程都到达屏障点后才会一块往下执行,这就保证了所有线程完成了阶段 1 后才会执行阶段 2。然后到达阶段 2 后,才能开始阶段 3 的执行。**CyclicBarrier 的复用性 这个功能使用单个 CountDownLatch 是无法完成的。**
实现原理
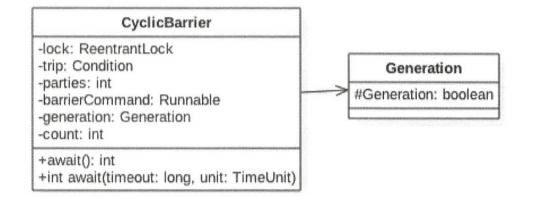
由上图可知,CyclicBarrier 居于独占锁实现,本质底层还是基于 AQS 的。**parties 用来记录线程个数,这里表示多少个线程调用 await 后,所有线程才会冲破屏障继续往下运行。而 count 一开始等于 parties ,每当有线程调用了 await 方法就递减 1,当 count 为 0时就表示所有线程都到了屏障点。你可能会疑惑,之所以维护 parties 和 count 两个变量, 是因为 CyclicBarrier 是可以被复用的,使用两个变量的原理时,parties 始终用来记录总的线程个数,当 count 计数器值变为 0 后,会将 parties 的值赋给 count,从而进行复用**。这两个变量是在构造 CyclicBarrier 对象时传递的。
CyclicBarrier 构造函数
//这里有两个变量 一个是线程个数 parties 另一个是一个任务,这个任务的执行时机是当所有线程都达到屏障点后。 |
CyclicBarrier 使用 lock 首先保证了更新计数器 count 的原子性。另外使用 lock 的条件变量 trip 支持线程间使用 await 和 signal 操作进行同步。
最后在变量内部有一个变量 broken ,其用来记录当前屏障是否被打破。(注意:这里的 broken 并没有被声明为 volatile 的,因为在锁内使用变量,所以不需要声明)
private static class Generation { |
下面来看 CyclicBarrier 中的几个重要的方法。
int await()方法
当前线程调用 CyclicBarrier 的该方法时会被阻塞,直到满足下面条件之一才会返回:
- parties 个线程都调用了 await() 方法,也就是线程都到了屏障点;
- 其他线程调用了当前线程的 interrupt() 方法中断了当前线程,则当前线程会抛出 interruptedException 异常而返回;
- 与当前屏障点关联的 Generation 对象的 broken 标志被设置为 true 时,会抛出
BrokenBarrierException异常,然后返回。
public int await() throws InterruptedException, BrokenBarrierException { |
如上代码可知,在内部调用了 dowait 方法。第一个参数为 false 则说明不设置超时时间,这时候第二个参数没有意义。
boolean await(long timeout, TimeUnit unit)方法
当前线程调用了 CyclicBarrier 的该方法时会被阻塞,直到满足下面条件之一才会返回:
- parties 个线程都调用了 await() 方法,也就是线程都到了屏障点,这时候返回 true;
- 设置的超时时间到了后返回 false;
- 其他线程调用了当前线程的 interrupt() 方法中断了当前线程,则当前线程会抛出 interruptedException 异常而返回;
- 与当前屏障点关联的 Generation 对象的 broken 标志被设置为 true 时,会抛出
BrokenBarrierException异常,然后返回。
public int await(long timeout, TimeUnit unit) |
如上代码可知,在内部调用了 dowait 方法。第一个参数为 true 则说明设置了超时时间,这时间第二个参数是超时时间。
int dowait(boolean timed, long nanos)方法
该方法实现了 CyclicBarrier 的核心功能。
private int dowait(boolean timed, long nanos) |
当一个线程调用了
dowait方法后,首先会获取独占锁,如果创建CyclicBarrier时传递的参数为 10,那么后面 9 个调用线程会被阻塞。然后当前获取到锁的线程会对计数器 count 进行递减操作,递减后 count = index = 9,因为 index!=0 所以当前线程会执行代码(4)。如果当前线程调用的是无参数的await()方法,则这里 timed=false,所以当前线程会被放入条件变量 trip 的条件阻塞队列,当前线程会被挂起并释放获取的 lock 锁。如果调用的是有参数的await方法则 time = true,然后当前线程也会被放入条件变量的条件队列并释放资源,不同的是当前线程会在指定时间超时后自动被激活。当第一个获取锁的线程由于被阻塞释放锁后,被阻塞的 9 个线程中有一个会竞争到 lock 锁,然后执行与第一个线程同样的操作,直到最后一个线程获取到 lock 锁,此时已经有 9 个线程被放入了 条件变量 trip 的条件队列里面。最后 count=index 等于 0,所以执行代码(2),如果创建
CyclicBarrier时传递了任务,则在其他线程被唤醒前执行任务,任务执行完毕后再执行代码(3),唤醒其他 9 个线程,并重置CyclicBarrier,然后这 10 个线程就可以继续向下运行了。
信号量 Semaphore 原理探究
Semaphore 信号量也是 Java 中的一个同步器,与 CountDownLatch 和 CyclicBarrier 不同的是,它内部的计数器是递增的,并且在一开始初始化 semaphore 时可以指定一个初始值,但是并不需要知道需要同步的线程个数,而是在需要同步的地方调用 acquire 方法时指定需要同步的线程个数。
案例介绍
同样下面的例子也是在主线程中开启两个子线程让他们执行,等所有子线程执行完毕后主线程再继续向下运行。
public class SemaphoreTest { |
输出结果如下。

如上代码首先创建了一个信号量实例,构造函数的入参为 0 ,说明当前信号量计数器的值为 0。然后 main 函数向线程池添加了两个线程池,在每个线程内部调用信号量的 release 方法,这相当于让计数器值递增 1。最后在 main 线程里面调用信号量的 acquire 方法,传参为 2 说明调用 acquire 方法的线程会一直阻塞,直到信号量的计数变为 2 才会返回。看到这里也就明白了,如果构造 Semaphore 时传递的参数为 N,并在 M 个线程中调用了该信号量的release 方法,那么在调用 acquire 使 M 个线程同步时传递的参数应该是 M + N。
下面举个例子来模拟 CyclicBarrier 复用的功能
public class SemaphoreTest2 { |
输出结果为
如上代码首先将线程 A 和线程 B 假如到线程池。主线程执行代码(1)后被阻塞。线程 A 和线程 B 调用
release方法后信号量的值变为了 2,这时候主线程的acquire方法会在获取到两个信号量后返回(返回后当前信号量值为 0)。然后主线程添加线程 C 和线程 D 到线程池,之后主线程执行代码(2)后被阻塞(因为主线程要获取 2 个信号量,而当前信号量个数为 0 )。当线程 C 和线程 D 执行完 release 方法后, 主线程才返回。从本例子可以看出,Semaphore 在某种程度上实现了CyclicBarrier的复用功能。
原理探究
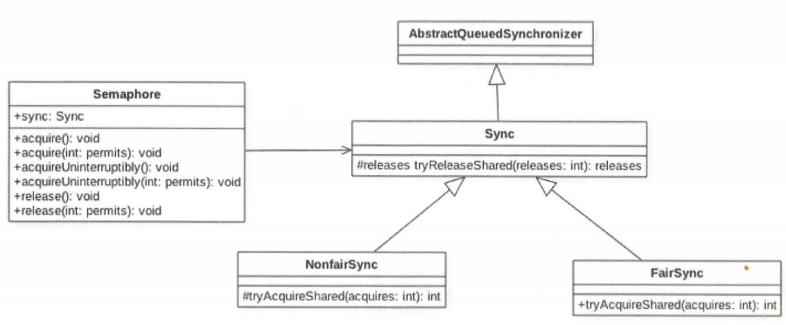
由该类图可知,Semaphore 还是使用 AQS 实现的。Sync 只是对 AQS 的一个修饰,并且 Sync 有两个实现类,用来指定获取信号量时是否采用公平策略。
下面的代码在创建 Semaphore 时会使用一个变量指定是否使用公平策略。
public Semaphore(int permits) { |
在如上代码中,Semaphore 默认采用非公平锁策略,如果需要使用公平策略则可以使用带两个参数的构造函数来构造 Semaphore 对象。另外,如 CountDownLatch 构造函数传递的初始化信号量个数 permits 被赋给了 AQS 的 state 状态变量一样,这里 AQS 的state 值也表示当前持有的信号量个数。
下面来看 Semaphore 实现的主要方法。
void acquire()方法
当前线程调用该方法的目的是希望获取一个信号量资源。如果当前信号量个数大于 0, 当前信号量的计数会减 1,然后该方法直接返回。否则如果当前信号量个数等于 0, 则当前线程会被放入 AQS 阻塞队列。当其他线程调用了当前线程的 interrupt() 方法中断了当前线程时,则当前线程会抛出 InterruptedExecption 异常返回。
public void acquire() throws InterruptedException { |
这里先讨论非公平策略 NonfairSync 类的 tryAcquireShared 方法。
protected int tryAcquireShared(int acquires) { |
由于 NonFairSync 是非公平获取的,也就是说先调用 aquire 方法获取信号量的线程不一定比后来者先获取到信号量。考虑下面场景,如果线程 A 先调用了 aquire() 方法获取信号量。但是当前信号量个数为 0,那么线程 A 会被放入 AQS 的阻塞线程。过一段时间后线程 C 调用了 release() 方法释放了一个信号量,如果当前没有其他线程获取信号量,那么线程 A 就会被激活,然后获取该信号量,但是假如线程 C 释放信号量后,线程 C 调用了 acquire 方法,那么线程 C 就会和线程 A 去竞争这个信号资源。如果采用非公平策略,由 nonfairTryAcquireShared 的代码可知,线程 C 完全可以在线程 A 被激活前,或者激活后先于线程 A 获取到信号量,也就是在这种模式下阻塞线程和当前请求的线程是竞争关系,而不遵循先来先得的策略。
下面来看公平策略实现的 FairSync
protected int tryAcquireShared(int acquires) { |
由上代码可知,公平性还是靠 hasQueuedPredecessors() 这个函数保证的。前面讲解过,公平策略是看当前线程节点的前驱节点是否也在等待获取该资源,如果是则自己放弃获取的权限,然后当前线程会被放入 AQS 阻塞队列,否则就去获取。
void acquire(int permits)方法
该方法与 acquire() 方法不同,后者只需要获取一个信号量值,而前者则获取 permits 个。
public void acquire(int permits) throws InterruptedException { |
void acquireUninterruptibly()方法
该方法与 acquire() 方法类似,不同之处在于该方法对中断不响应,也就是线程调用了 acquireUninterruptibly() 获取资源时(包含被阻塞后),其他线程调用了当前线程的 interrupt() 方法设置了当前线程的中断标志,此时当前线程并不会抛出 InterruptedException 异常而返回。
public void acquireUninterruptibly() { |
void acquireUninterruptibly(int permits)方法
该方法与 acquire(int permits) 方法的不同之处在于,该方法对中断不响应。
public void acquireUninterruptibly(int permits) { |
void release()方法
该方法的作用是把当前 Semaphore 对象的信号量值增加 1,如果当前有其他线程因为调用 acquire 方法而被阻塞而被放入了 AQS 的阻塞线程,则会根据公平策略选择一个信号量个数能被满足的线程进行激活,激活的线程会尝试获取刚增加的信号量。
public void release() { |
由代码 release() -> sync.releaseShared(1) 可知,release 方法每次只会对信号量值增加 1,tryReleaseShared 方法是无限循环,使用 CAS 保证了 release 方法对信号量递增 1 的原子性操作。tryReleaseShared 方法增加信号量成功后会执行代码(3),即调用 AQS 方法来激活因为调用 acquire 方法而被阻塞的线程。
void release(int permits)方法
该方法于不带参的 release 方法的不同之处在于,前者每次调用会在信号量值原来的基础上增加 permits,而后者每次增加 1。
public void release(int permits) { |
另外,这里的 sync.releaseShared 是共享方法,这说明该信号量是线程共享的,信号量没有和固定线程绑定,多个线程可以同时使用 CAS 去更新信号量的值而不会被阻塞。
第 11 章 并发编程实践
ArrayBlockingQueue 的使用
异步日志打印模型概述
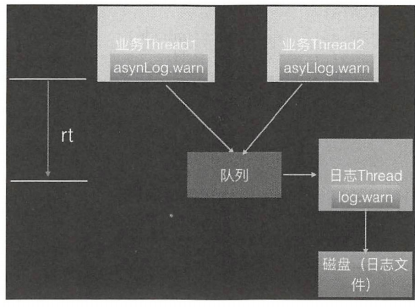
在高并发、高流量并且响应时间要求比较小的系统中同步打印日志已经满足不了需求了,这是因为打印日志本身是需要写磁盘的,写磁盘的操作会暂时阻塞调用打印日志的业务线程,这会造成调用线程的 增加 如图示为同步日志打印模型

同步日志打印模型的缺点是将日志写入磁盘的操作是业务线程同步调用完成的,那么是否可以让业务线程把要打印的日志任务放入一个队列后直接返回,然后使用一个线程专门负责从队列中获取日志任务并将其写入磁盘呢?这样的话,业务线程打印日志的耗时就仅仅是把日志任务放入队列的耗时了,其实这就是 logback 提供的异步日 打印模型要做的事,具体如图所示。
异步日志与具体实现
- 异步日志
一般配置同步日志打印时会在 logback 的 xml 文件里面配置如下内容。

